Ever hit a wall while scraping JavaScript-rendered web pages with Python?
Well, that's understandable.
It can certainly prove difficult because of their dynamically loaded data. Not to mention there are loads of web apps using frameworks like React.js or Angular, so there's a high chance your request-based scraper may break while trying to perform.
By now, you've probably realized that the standard libraries and methods aren't enough to scrape JS-generated content. Don't worry! In this tutorial, you'll get just the right tips to get the job done.
Are you ready to learn how to scrape JavaScript-rendered web pages with Python? Let's go:
Why is Scraping JavaScript-Rendered Web Pages Difficult?
When you send a request to a web page, the client downloads the content (which is different when it comes to JS websites). If the client supports JavaScript, it'll run the code to populate the rendered HTML content.
That being said...
These pages don't really produce valuable static HTML content. As a result, plain HTTP requests won't be enough as the requested content must be populated first.
This means you have to write code specifically for each target website. And that's what makes scraping JavaScript content so difficult.
Of course, there are other options. Let's look at the different ways of rendering the web page:
- Static rendering: this happens at build-time and offers a fast user experience. The main downside is that individual HTML files must be generated for every possible URL.
As we know, it's pretty easy to scrape data from static websites.
- Server rendering: it generates the complete HTML for a page on the server in response to navigation. This avoids extra data fetching on the client's side since it's handled before the browser gets a response.
Just like a static website, we can extract information by sending simple HTTP requests as the entire content returns from the server.
- Client-side rendering: pages are rendered directly in the browser using JavaScript. The logic, data fetching, and routing are handled on the client's side rather than the server.
Nowadays, many modern apps combine the last two approaches in an attempt to smooth over their disadvantages. This is often referred to as Universal Rendering.
It's also supported by popular frameworks such as React.js and Angular. For example, React parses the HTML and updates the rendered page dynamically---a process called hydration.
How to Scrape JavaScript-Generated Content
There are a variety of different methods available. Let's explore two of them:
Using Backend Queries
Sometimes frameworks such as React populate the page by using backend queries. It's possible to use these API calls in your application, getting data directly from the server.
However, this isn't guaranteed. This means you'll need to check your browser requests to find out if there's an available API backend in the first place. If there is one, then you can use the same settings with your custom queries to grab the data.
Using Script Tags
So, what's another method you can use to scrape JavaScript-generated content from web pages?
You can try using hidden data in a script tag as a JSON file. However, you should know that this might require a deep search since you'll be checking the HTML tags on the loaded page. The JS codes can be extracted using the BeautifulSoup Python package.
Web applications usually protect API endpoints using different authentication methods, so employing APIs for scraping JS-rendered pages may be challenging.
If there's encoded hidden data present in the static content, you may not be able to decode it. In this case, you need software that can render JavaScript for scraping.
You can try browser-based automation tools, e.g., Selenium, Playwright, or Puppeteer. In this guide, we'll test how Selenium in Python works (note that it's also available for JavaScript and Node.js).
How to Build a Web Scraper with Selenium
Selenium is primarily used for web testing. Its ability to work like an actual browser places it among the best options for web scraping as well.
Since it also supports JS, scraping JavaScript-rendered web pages with Selenium shouldn't be an issue.
In this tutorial, we won't be exploring all the complex methods you can use. Check out our thorough Selenium guide to learn all about that and more. However, here we'll focus on else:
Let's try scraping [Sprouts’ breads] (https://www.instacart.com/store/sprouts/collections/bread/872?guest=true) from Instacart.
At first, the website renders a template page on the server; then, it gets populated by JavaScript on the client's side.
Here's what the loading screen looks like:

After populating the HTML content, we get something like this:

Now that we've covered the basics, let's get down to scraping JavaScript-rendered web pages with Selenium on Python!
Installing the Requirements
Selenium is used to control a web driver instance. Selenium WebDriver used to need its own setup, but now it comes with Selenium version 4 and up. If you have an older version, you can update it to get the new stuff. Just type 'pip show selenium' to see what you have, and 'pip install --upgrade selenium' to get the latest.
The data will be stored in a CSV format by using the Pandas module.
We must then install the packages by using pip:
pip install selenium pandas
Alright! Finally, we can get to scraping.
We'll start by importing the necessary modules:
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
Now, let's initialize the headless chrome web driver:
# Define the Chrome webdriver options
options = webdriver.ChromeOptions()
options.add_argument("--headless") # Set the Chrome webdriver to run in headless mode for scalability
# By default, Selenium waits for all resources to download before taking actions.
# However, we don't need it as the page is populated with dynamically generated JavaScript code.
options.page_load_strategy = "none"
# Pass the defined options objects to initialize the web driver
driver = Chrome(options=options)
# Set an implicit wait of 5 seconds to allow time for elements to appear before throwing an exception
driver.implicitly_wait(5)
After that, we'll connect to the website:
url = "https://www.instacart.com/store/sprouts/collections/bread/872?guest=true"
driver.get(url)
time.sleep(20)
You'll notice that we added a 20 seconds delay. That's done to let the driver load the website completely.
Before we move on to extracting data from individual listings, we must find out where the products are stored.
They are saved as a li element inside of the ul, which, in turn, is in a div one:

We can sort out the div elements by filtering their classes by substrings.
Next, we have to check if their class attribute has the e-14cjhfa text. You can use the CSS selectors for this:
content = driver.find_element(By.CSS_SELECTOR, "div[class*='e-14cjhfa'")
The *= will come in handy when making sure if a specific substring is in the attribute. As there aren't any li elements outside of the ul parent, we'll extract the ones from content:
breads = content.find_elements(By.TAG_NAME, "li")
Next up, we'll scrape the JS-generated data from every single li element individually:

Let's start by extracting the product image. You'll notice two things: there's only one img element in the li, and the image URLs are visible in the srcset attribute:

We now need to process the extracted data.
After a bit of digging, you can see the image is stored in CloudFront CDN. From there, we can extract the URL.
Split the whole element by , [take note of the space after the comma] and process the first part. We break the URL with / and link together the parts starting from the Cloudfront one:
def parse_img_url(url):
# get the first url
url = url.split(', ')[0]
# split it by '/'
splitted_url = url.split('/')
# loop over the elements to find where 'cloudfront' url begins
for idx, part in enumerate(splitted_url):
if 'cloudfront' in part:
# add the HTTP scheme and concatenate the rest of the URL
# then return the processed url
return 'https://' + '/'.join(splitted_url[idx:])
# as we don't know if that's the only measurement to take,
# return None if the cloudfront couldn't be found
return None
Time to extract the URL by using the parse_img_url function:
img = element.find_element(By.TAG_NAME, "img").get_attribute("srcset")
img = parse_img_url(img)
As you can see, there are dietary attributes only on some of the products.
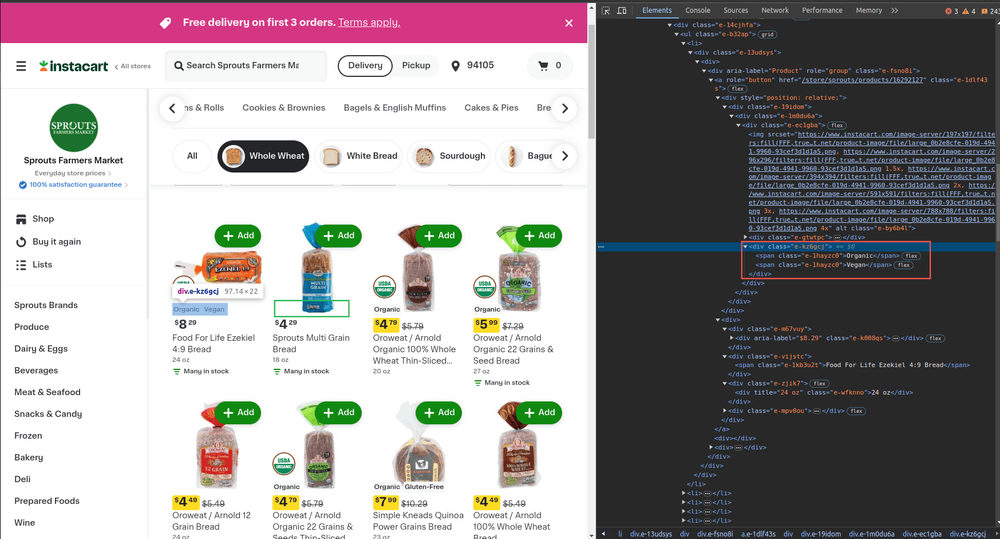
Time to employ the CSS selectors to extract the spans inside of the div element. After that, we'll use the find_elements method in Selenium. If it returns None, that means there aren't any span elements:
# A>B means the B elements where A is the parent element.
dietary_attrs = element.find_elements(By.CSS_SELECTOR, "div[class*='e-kz6gcj']>span")
# if there aren't any, then 'dietary_attrs' will be None and 'if' block won't work
# but if there are any dietary attributes, extract the text from them
if dietary_attrs:
dietary_attrs = [attr.get_attribute("textContent") for attr in dietary_attrs]
else:
# set the variable to None if there aren't any dietary attributes found.
dietary_attrs = None
Moving on to prices...
Prices are stored in a div element with the e-k008qs as the class attribute. Since it's not the only one, we'll directly get the span element by using CSS selectors:
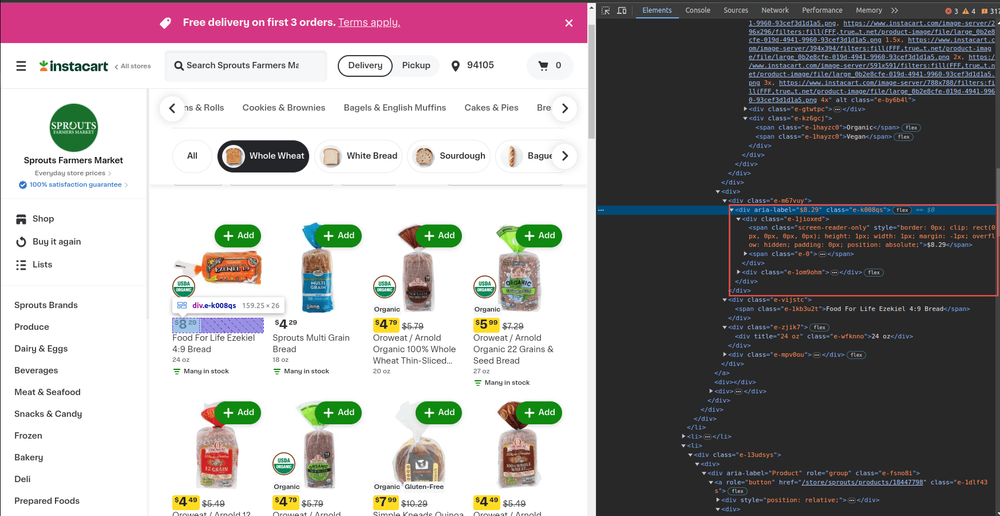
It's always a good idea to check if the element is loaded while scraping the prices on the web page.
A simple approach would be the find_elements method.
It returns an empty list, which can be helpful for building a data extraction API:
# get the div>span elements where the parent is a 'div' element that
# has 'e-k008qs' string in the 'class' attribute
price = element.find_elements(By.CSS_SELECTOR, "div[class*='e-k008qs']>div>span")
# extract the price text if we could find the price span
if price:
price = price[0].get_attribute("textContent")
else:
price = None
Finally, we'll retrieve the name and size of the product.
The name is stored in the span element with the class e-1kb3u2t. As for the size, we'll once again rely on a CSS selector for the job:
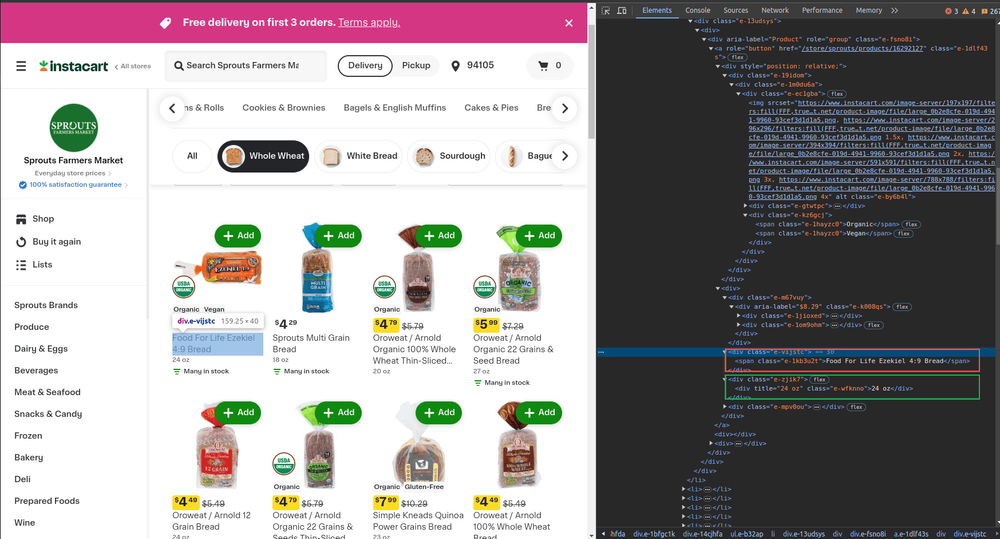
Now that that's all taken care of, we have to add the following code:
name = element.find_element(By.CSS_SELECTOR, "span[class*='e-1kb3u2t']").get_attribute("textContent")
size = element.find_element(By.CSS_SELECTOR, "div[class*='e-wfknno']").get_attribute("textContent")
Finally, we can wrap all this within an extract_data function:
def extract_data(element):
# get the 'img' element and extract the 'srcset' attribute
img = element.find_element(By.TAG_NAME, "img").get_attribute("srcset")
img = parse_img_url(img)
# A>B means the B elements where A is the parent element.
dietary_attrs = element.find_elements(By.CSS_SELECTOR, "div[class*='e-kz6gcj']>span")
# if there aren't any, then 'dietary_attrs' will be None and 'if' block won't work
# but if there are any dietary attributes, extract the text from them
if dietary_attrs:
dietary_attrs = [attr.get_attribute("textContent") for attr in dietary_attrs]
else:
# set the variable to None if there aren't any dietary attributes found.
dietary_attrs = None
# get the div>span elements where the parent is a 'div' element that
# has 'e-k008qs' string in the 'class' attribute
price = element.find_elements(By.CSS_SELECTOR, "div[class*='e-k008qs']>div>span")
# extract the price text if we could find the price span
if price:
price = price[0].get_attribute("textContent")
else:
price = None
name = element.find_element(By.CSS_SELECTOR, "span[class*='e-1kb3u2t']").get_attribute("textContent")
size = element.find_element(By.CSS_SELECTOR, "div[class*='e-wfknno']").get_attribute("textContent")
return {
"price": price,
"name": name,
"size": size,
"attrs": dietary_attrs,
"img": img
}
Let's use that to process all li elements found in the main content div. It's possible to store the results in a list and convert them to a DataFrame by using Pandas!
data = []
for bread in breads:
extracted_data = extract_data(bread)
data.append(extracted_data)
df = pd.DataFrame(data)
df.to_csv("result.csv", index=False)
And there you have it! A Selenium scraper that extracts data from JavaScript-rendered websites! Easy, right?
Here's what your final result should look like if you followed this step-by-step tutorial meticulously:
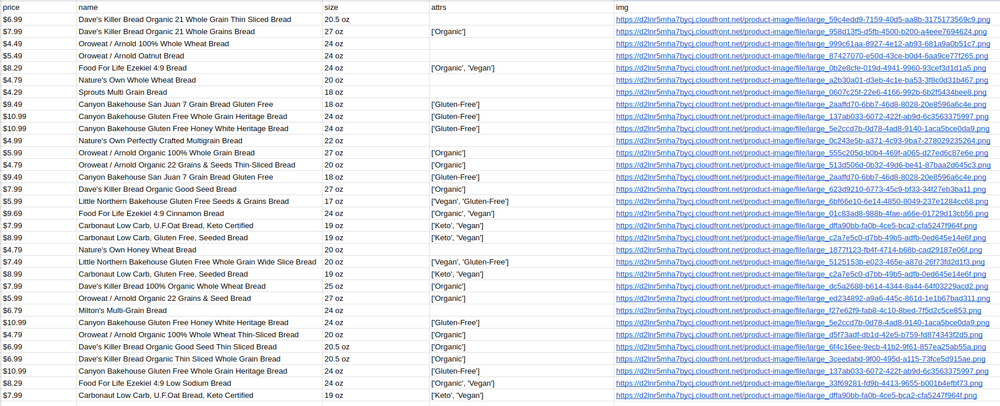
A scraped data from a JavaScript-rendered web page using Python.
The Disadvantage of using Selenium
Since we're running web driver instances, it's difficult to scale up the application. More of them will need more resources, which will overload the production environment.
You should also keep in mind that using a web driver is more time-consuming compared to request-based solutions. Therefore, it's generally advised to use such browser-automation tools, that is Selenium, as a last resort.
Conclusion
Today you learned how to scrape JavaScript-generated content from dynamically loaded web pages.
We covered how JS-rendered websites work. We used Selenium to build a dynamic data extraction tool.
Let's do a quick recap:
-
Install Selenium.
-
Connect to the target URL.
-
Scrape the relevant data using CSS selectors or another method Selenium supports.
-
Save and export the data as a CSV file for later use.
Of course, you can always build your own web scraper. Though, there are many difficulties that come with that decision. Just think of the numerous antibot protections websites employ. Not to mention that scraping dozens of products and/or websites is extremely difficult and time-consuming.
So, why don't you let professionals take this load off your hands? ZenRows lets you scrape data with simple API calls. It also handles the anti-bot measures automatically. Try it out for free today!
Did you find the content helpful? Spread the word and share it on Twitter, or LinkedIn.