Extract Data from Lists, Tables, and Grids
We’ll explore popular use cases for scraping, such as lists, tables, and product grids. Use these as inspiration and a guide for your scrapers.
Scraping from Lists
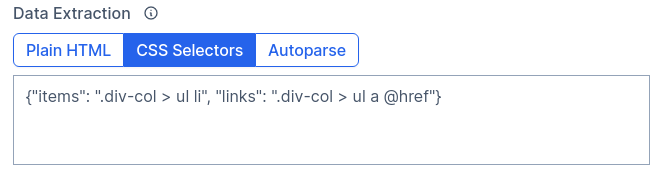
We will use the Wikipedia page on Web scraping for testing. A section at the bottom, “See also”, contains links in a list. We can get the content by using the CSS selector for the list items: {"items": ".div-col > ul li"}. That will get the text, but what of the links? To access attributes, we need a non-standard syntax for selector: @href. It won’t work with the previous selector since the last item is the li element, which does not have an href attribute. So we must change it for the link element: {"links": ".div-col > ul a @href"}.
CSS selectors must be encoded to avoid problems with URLs.
curl "https://api.zenrows.com/v1/?apikey=YOUR_ZENROWS_API_KEY&url=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FWeb_scraping&css_extractor=%257B%2522items%2522%253A%2520%2522.div-col%2520%253E%2520ul%2520li%2522%252C%2520%2522links%2522%253A%2520%2522.div-col%2520%253E%2520ul%2520a%2520%2540href%2522%257D"
You can take advantage of our Builder to help you write and test the selectors. It will also output code in several languages.
Scraping from Tables
Assuming regular tables (no empty cells, rows with fewer items, and others), we can extract table data with CSS selectors. We’ll use a list of countries, the first table on the page, the one with the class wikitable.
To extract the rank, which is the first column, we can use "table.wikitable tr > :first-child". It will return an array with 243 items, 2 header lines, and 241 ranks. For the country name, second column, something similar but adding an a to avoid capturing the flags: "table.wikitable tr > :nth-child(2) a". In this case, the array will have one less item since the second heading has no link. That might be a problem if we want to match items by array index.
curl "https://api.zenrows.com/v1/?apikey=YOUR_ZENROWS_API_KEY&url=https%3A%2F%2Fen.m.wikipedia.org%2Fwiki%2FList_of_countries_and_dependencies_by_population&css_extractor=%257B%2522rank%2522%253A%2520%2522table.wikitable%2520tr%2520%253E%2520%253Afirst-child%2522%252C%2520%2522countries%2522%253A%2520%2522table.wikitable%2520tr%2520%253E%2520%253Anth-child%282%29%2520a%2522%257D"
Outputs:
{
"countries": ["Country or dependent territory", "China", "India", ...],
"rank": ["Rank", "-", "1", "2", ...]
}
As stated above, this might prove difficult for non-regular tables. And for those, we might prefer to get the Plain HTML and scrape the content with a tool or library so we can add conditionals and logic.
And this example has listed items by column, not row, which might prove helpful for a variety of cases. There are no easy ways to extract structured data from tables using CSS Selectors and group them by row.
Scraping from Product Grids
As with the tables, non-regular grids might cause problems. We’ll scrape the price, product name, and link from an online store. By manually searching content on the page, we arrive at cards with the class product-card. Those contain all the data we want.
It is important to avoid duplicates, so we have to use some precise selectors. For example, "#collection-content .product-card .card-inner > a @href" for the links. We added the .card-inner wrapper class because there are two links inside the product card. The same goes for name and price, wrapped in a product-meta-large that has a similar one for smaller screens.
All in all, the final selector would be:
{
"links": "#collection-content .product-card .card-inner > a @href",
"names": "#collection-content .product-card .product-meta-large .product-title .title",
"prices": "#collection-content .product-card .product-meta-large .formatted-product-price"
}
At the moment of this writing, there are 27 items on the page. And each array has 27 elements, so everything looks fine. If we were to group them, we could zip the arrays.
Example in python, taking advantage of the auto-encoding that requests.get does to parameters. For different scenarios when that is not available, remember to encode the URL and CSS extractor.
# pip install requests
import requests
import json
zenrows_api_base = "https://api.zenrows.com/v1/?apikey=YOUR_ZENROWS_API_KEY"
url = "https://www.3sixteen.com/collections/shirts"
css_extractor = """{
"links": "#collection-content .product-card .card-inner > a @href",
"names": "#collection-content .product-card .product-meta-large .product-title .title",
"prices": "#collection-content .product-card .product-meta-large .formatted-product-price"
}"""
response = requests.get(zenrows_api_base, params={
"url": url, "css_extractor": css_extractor})
parsed_json = json.loads(response.text)
result = zip(parsed_json["links"], parsed_json["names"], parsed_json["prices"])
print(list(result))
# [('/collections/shirts/products/block-bd-shirt-earth', 'Patchwork BD Shirt', '$240.00'), ... ]
Keep in mind that this approach won’t work properly if, for example, some products have no price. Not all the arrays would have the same length, and the zipping would misassign data. For those cases, getting the Plain HTML and parsing the content with a library and custom logic is a better solution.
If there is any problem or you cannot correctly set up your scraper, contact us and we’ll help you.