How to Extract Data
ZenRows offers the option to extract data directly in the API call using CSS Selectors. Activate it with the param css_extractor. That will return a JSON object instead of the Plain HTML. If you already have some solutions implemented or prefer to write your own, you can get the Plain HTML and pass it to a library like BeautifulSoup (python) or Cheerio (javascript).
Using CSS Selectors
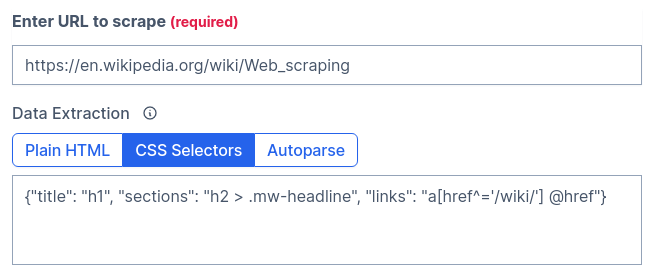
Let’s say we want to scrape the Wikipedia page on Web scraping. Just for testing, we will retrieve its title, which is an h1. For that, we need to send the css_extractor parameter with the value {"title": "h1"}. Careful here since it must be encoded.
curl "https://api.zenrows.com/v1/?apikey=YOUR_ZENROWS_API_KEY&url=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FWeb_scraping&css_extractor=%257B%2522title%2522%253A%2520%2522h1%2522%257D"
Now, a step further. A second item: section headings using the selector h2 > .mw-headline.
curl "https://api.zenrows.com/v1/?apikey=YOUR_ZENROWS_API_KEY&url=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FWeb_scraping&css_extractor=%257B%2522title%2522%253A%2520%2522h1%2522%252C%2520%2522sections%2522%253A%2520%2522h2%2520%253E%2520.mw-headline%2522%257D"
Will output:
{
"sections": [
"History",
"Techniques",
"Software",
"Legal issues",
"Methods to prevent web scraping",
"See also",
"References"
],
"title": "Web scraping"
}
To continue scraping new articles, we will need a list of links. But we can filter them by checking that the link starts with /wiki/. To get an attribute instead of the text content, we can add @href: "links": "a[href^='/wiki/'] @href".
curl "https://api.zenrows.com/v1/?apikey=YOUR_ZENROWS_API_KEY&url=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FWeb_scraping&css_extractor=%257B%2522title%2522%253A%2520%2522h1%2522%252C%2520%2522sections%2522%253A%2520%2522h2%2520%253E%2520.mw-headline%2522%252C%2520%2522links%2522%253A%2520%2522a%255Bhref%255E%253D%27%252Fwiki%252F%27%255D%2520%2540href%2522%257D"
{
"links": [
"/wiki/Data_scraping",
"/wiki/Data_extraction",
// ...
],
"sections": [
// ...
],
"title": "Web scraping"
}
Before going full scale, you can test your selectors and get the encoded results in our Builder. It will also output code in several languages.
For more details, check the documentation.
Using External Libraries
You can still use your favorite library to scrape the content from the HTML. Libraries like BeautifulSoup and Cheerio are agnostic to where the HTML comes from. So we can take advantage of that and get it from ZenRows as Plain HTML and pass it to the library for processing.
Python with BeautifulSoup
# pip install requests beautifulsoup4
import requests
from bs4 import BeautifulSoup
zenrows_api_base = "https://api.zenrows.com/v1/?apikey=YOUR_ZENROWS_API_KEY"
url = "https://en.wikipedia.org/wiki/Web_scraping"
response = requests.get(zenrows_api_base, params={'url': url})
soup = BeautifulSoup(response.text, "html.parser")
title = soup.find("h1").text
sections = [section.text for section in soup.select("h2 > .mw-headline")]
links = [link.get("href") for link in soup.select("a[href^='/wiki/']")]
result = {
"title": title,
"sections": sections,
"links": links[5:7],
}
print(result)
JavaScript with Cheerio
// npm i axios cheerio
const axios = require("axios");
const cheerio = require("cheerio");
const zenrows_api_base = "https://api.zenrows.com/v1/?apikey=YOUR_ZENROWS_API_KEY";
const url = "https://en.wikipedia.org/wiki/Web_scraping";
axios
.get(zenrows_api_base, { params: { url } })
.then((response) => {
const $ = cheerio.load(response.data);
const title = $("h1").text();
const sections = $("h2 > .mw-headline")
.map((_, a) => $(a).text())
.toArray();
const links = $("a[href^='/wiki/']")
.map((_, a) => $(a).attr("href"))
.toArray();
console.log({ title, sections, links: links.slice(5, 7) });
})
.catch((error) => console.log(error));