DOs and DON'Ts of Web Scraping
Learn how to create better web scrapers by following best practices and avoiding common mistakes. Choose the right approach for the job thanks to these tips.
For those of you new to web scraping, regular users, or just curious: these tips are golden. Scraping might seem like an easy-entry activity, and it is. But it'll take you down a rabbit hole. Before you realize it, you got blocked from a website, your code is 110% spaghetti, and there's no way you can scale that to another four sites.
Ever been there? ✋We were there ten years ago; no shame (well, just a bit). Continue with us for a few minutes, and we'll help you navigate through the rabbit hole. 🕳️
DO Rotate IPs
The simplest and most common anti-scraping technique is to ban by IP. Whether through WAF bypass systems like Cloudflare or custom solutions, the server will show you the first pages, but it'll detect too much traffic from the same IP and block it after some time. Then your scraper will be unusable. And you won't even be able to access the webpage from a real browser. The first lesson on web scraping is never to use your actual IP.
Every request leaves a trace, even if you try to avoid it from your code. There are some parts of networking that you can't control. But you can use a proxy to change your IP. The server will see an IP, but it won't be yours. The next step, rotate the IP or use a service that will do it for you. What does this even mean?
You can use a different IP every few seconds or per request. The target server can't identify your requests and won't block those IPs. You can build a massive list of proxies and take one randomly for every request. Or use a rotating proxy, which will do that for you. Either way. Your chances of succesful scraping without getting blocked will be higher.
import requests
import random
urls = ["http://ident.me"] # ... more URLs
proxy_list = [
"54.37.160.88:1080",
"18.222.22.12:3128",
# ... more proxy IPs
]
for url in urls:
proxy = random.choice(proxy_list)
proxies = {"http": f"http://{proxy}", "https": f"http://{proxy}"}
response = requests.get(url, proxies=proxies)
print(response.text)
# prints 54.37.160.88 (or any other proxy IP)
BoldNote that these free proxies might not work for you. They are short-time lived.
Skip the blocks. Try Zenrows free and get clean web data without the anti-bot fight.
DO Use Custom User-Agent
The second-most-common anti-scraping mechanism is User-Agent. UA is a header that browsers send in requests to identify themselves. It's usually a long string declaring the browser's name, version, platform, etc. An example of an iPhone 13:
"Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"
There is nothing wrong with sending a User-Agent, and it's actually recommended to do so. The problem is which one to send. Many HTTP clients send their own (cURL, Requests in Python, or Axios in JavaScript), which might be suspicious.
Can you imagine your server getting hundreds of requests with a curl/7.74.0 UA? You'd be skeptical, at the very least.
The solution is usually finding valid UAs, like the one from the iPhone above, and using them. But it might turn against you also. Thousands of requests with exactly the same version in short periods?
So the next step is to have several valid and modern User-Agents, use them, and keep the list updated. As with the IPs, rotate the UA in every request in your code.
# ... same as above
user_agents = [
"Mozilla/5.0 (iPhone ...",
"Mozilla/5.0 (Windows ...",
# ... more User-Agents
]
for url in urls:
proxy = random.choice(proxy_list)
proxies = {"http": f"http://{proxy}", "https": f"http://{proxy}"}
response = requests.get(url, proxies=proxies)
print(response.text)
Bold## DO Research Target Content {#research-target-content} Take a look at the source code before starting development. Many websites offer more manageable ways to scrape data than CSS selectors.
A standard method of exposing data is through rich snippets, for example, via Schema.org JSON or itemprop data attributes. Others use hidden inputs for internal purposes (i.e., IDs, categories, product code), and you can take advantage. There's more than meets the eye.

Some other sites rely on XHR requests after the first load to get the data. And it comes structured! For us, the easier way is to browse the site with DevTools open and check both the HTML and Network tab. You'll have a clear vision and decide how to extract the data in a few minutes.
These tricks aren't always available, but you can save a headache using them. Metadata, for example, tends to change less than HTML or CSS classes, making it more reliable and maintainable long-term.
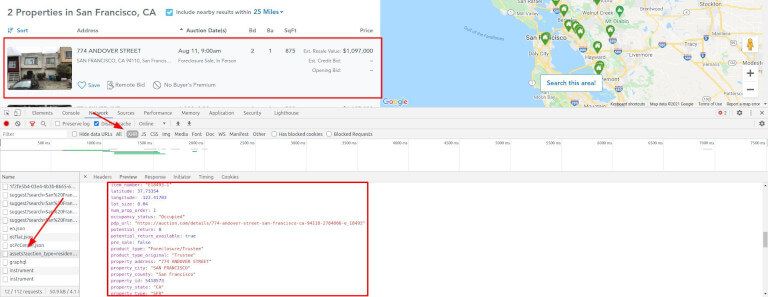
We wrote about exploring before coding with examples and code in Python; check out for more info.
DO Parallelize Requests
After switching gears and scaling up, the old one-file sequential script won't be enough. You probably need to "professionalize" it. For a tiny target and a few URLs, getting them one by one might be enough. But then scale it to thousands and different domains. It won't work correctly.
One of the first steps of that scaling would be to get several URLs simultaneously and not stop the whole scraping for a slow response. Going from a 50-line script to Google scale is a giant leap, but the first steps are achievable. There are the main things you'll need: concurrency and a queue.
Concurrency
The main idea is to send multiple requests simultaneously but with a limit. And then send a new one as soon as a response arrives. Let's say the limit is ten. That would mean that ten URLs would always be running at any given time until there are no more, which brings us to the next step.
We wrote a guide on using concurrency (examples in Python and JavaScript).
Queue
A queue is a data structure that allows adding items to be processed later. You can start crawling with a single URL, get the HTML and extract the links you want. Add those to the queue, and they'll start running.
Keep on doing the same, and you built a scalable crawler. Some points are missing, like deduplicating URLs (not crawling the same one twice) or infinite loops. But the easy way to solve it would be to set a maximum number of pages crawled and stop once you get there.
We have an article with an example in Python scraping from a seed URL.
Still far from Google scale (obviously), but you can go to thousands of pages with this approach. To be more precise, you can have different settings per domain to avoid overloading a single target. We'll leave that up to you 😉
DON'T Use Headless Browsers for Everything
Selenium, Puppeteer, and Playwright are great, no doubt, but not a silver bullet. They bring a resource overhead and slow down the scraping process. So why use them? 100% needed for JavaScript-rendered content and helpful in many circumstances. But ask yourself if that's your case.
Most sites serve the data, one way or another, on the first HTML request. Because of that, we advocate going the other way around. Test first plain HTML by using your favorite tool and language (cURL, Requests in Python, Axios in JavaScript, etc.).
Check for the content you need: text, IDs, and prices. Be careful here since sometimes the data you see on the browser might be encoded (i.e.," shown in plain HTML as "). Copy and paste might not work. 😅
Sometimes, you won't find the info because it's not there on the first load, for example, in Angular.io. No problem; headless browsers come in handy for those cases. Or XHR scraping as shown above for Auction.
If you find the info, try to write the extractors. A quick hack might be good enough for a test. Once you have identified all the content you want, the following point is to separate the generic crawling code from the custom one for the target site.
We did a small-scale benchmark with ten URLs using three methods to obtain the HTML.
- Using Python's
Requests: 2.41 seconds - Playwright with Chromium opening a new browser per request: 11.33 seconds
- Playwright with Chromium sharing browser and context for all the URLs: 7.13 seconds
It's not 100% conclusive nor statistically accurate, but it shows the difference. In the best case, using Playwright is about three times slower, and sharing context isn't always a good idea. And we're not even talking about CPU and memory consumption.
DON'T Couple Code to Target
Some actions are independent of the website you're scraping: get HTML, parse it, queue new links to crawl, store content, and more. In an ideal scenario, we would separate those from the ones that depend on the target site: CSS selectors, URL structure, and DDBB structure.
The first script is usually entangled; no problem there. But as it grows and new pages are added, separating responsibilities is crucial. We know it's easier said than done. But to pause and think matters to develop a maintainable and scalable scraper.
We published a repository and blog post about distributed crawling in Python. It's a bit more complicated than what we've seen so far. It uses external software (Celery for the asynchronous task queue and Redis as the database).
Long story short, separate and abstract the parts related to target sites. In our example, we simplified by creating a single file per domain. In there, we specify four things:
- How to get the HTML (Requests vs. headless browser)
- Filter URLs to queue for crawling
- What content to extract (CSS selectors)
- Where to store the data (a list in Redis)
# ...
def extract_content(url, soup):
# ...
def store_content(url, content):
# ...
def allow_url_filter(url):
# ...
def get_html(url):
return headless_chromium.get_html(url, headers=random_headers(), proxies=random_proxies())
_Italic_It's still far from massive-scale production-ready. But code reuse is easy, as is adding new domains. And when adding updated browsers or headers, it would be easy to modify the old scrapers to use those.
DON'T Take Down Your Target Site
Your extra load might be a drop in the ocean for Amazon but a burden for a small independent store. Be mindful of the scale of your scraping and the size of your targets.
You can probably crawl hundreds of pages at Amazon concurrently, and they won't even notice (be careful, nonetheless). But many websites run on a single shared machine with poor specs, and they deserve our understanding. Tune down your script capabilities for those sites. It might complicate the code, but stopping if the response times increase would be nice.
Another point is to inspect and comply with their robots.txt. Mainly two rules: do not scrape disallowed pages and obey Crawl-Delay. That directive isn't common, but when present, it represents the number of seconds crawlers should wait between requests. There is a Python module that can help us to comply with robots.txt.
We won't go into details but don't perform malicious activities (there should be no need to say it, just in case). We're always talking about extracting data without breaking the law or causing damage to the target site.
DON'T Mix Headers from Different Browsers
This last technique is for higher-level anti-bot solutions. Browsers send several headers with a set format that varies from version to version. And advanced solutions check those and compare them to a real-world header set database.
Which means you'll raise red flags when sending the wrong ones. Or even more difficult to notice by not sending the right ones! Visit HTTPBin to see the headers your browser sends. Probably more than you imagine and some you haven't even heard of! Sec-Ch-Ua? 😕
There is no easy way out of this but to have an actual full set of headers. And to have plenty of them, one for each User-Agent you use. Not one for Chrome and another for iPhone, nope. One. Per. User-Agent. 🤯
Some people try to avoid this by using headless browsers, but we've already seen why that's not better. And anyway, you're not in the clear with them. They send the whole header set that works for that browser on that version.
If you modify any of that, the rest might not be valid. If using Chrome with Puppeteer and overwriting the UA to use the iPhone one... you can have a surprise. A real iPhone doesn't send Sec-Ch-Ua, but Puppeteer will since you overwrote UA but didn't delete that one.
Some sites offer a list of User-Agents. But it's hard to get the complete sets for hundreds of them, which is the needed scale when scraping at complex sites.
# ...
header_sets = [
{
"Accept-Encoding": "gzip, deflate, br",
"Cache-Control": "no-cache",
"User-Agent": "Mozilla/5.0 (iPhone ...",
# ...
}, {
"User-Agent": "Mozilla/5.0 (Windows ...",
# ...
},
# ... more header sets
]
for url in urls:
# ...
headers = random.choice(header_sets)
response = requests.get(url, proxies=proxies, headers=headers)
print(response.text)
BoldThis last one was a bit picky. But some anti-scraping solutions can be super-picky and even more than headers. Some might check browser or even connection fingerprinting, so high-level stuff.
Related: How Much Does Web Scraping Cost?
Conclusion
Rotating IPs and having good headers will allow you to crawl and scrape most websites. Use headless browsers only when necessary and apply Software Engineering good practices.
Build small and grow from there, adding functionalities and use cases. But always keep scale and maintainability in mind while keeping success rates high. Don't despair if you get blocked from time to time, and learn from every case.
Web scraping at scale is a challenging and long journey, but you may not need the best system ever nor a 100% accuracy. Don't get stuck looking for perfection, just focus on finding the best way to scrape for your use case.
In case of doubts, questions, or suggestions, don't hesitate to contact us.