HttpClient User Agent in C#: How to Set It
Learn how to set and rotate the User Agent in C#'s HttpClient to avoid getting blocked while web scraping.

When you're trying to scrape websites with C# and HttpClient, the biggest headache is constantly getting blocked. Websites can spot you coming from a mile away because HttpClient's default headers practically scream "I'M A BOT!" The User-Agent string is the dead giveaway.
I'll show you how to fly under the radar by setting up a custom User-Agent in your C# HttpClient.
What Is the HttpClient User Agent?
HTTP request headers are vital pieces of information sent along with every HTTP request. They convey various details, and one of its key elements is the User-Agent (UA) string.
The UA serves as an identifier for the client making the request, informing the web server of its application, version, device, and even operating system. Here's a sample:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36
It reveals that the client is using the Chrome browser version 111 on a 64-bit Windows 10 operating system, among other information.
But in your scraper, your C# HttpClient User Agent tells the web server that you're not requesting from an actual browser, as it's an empty string by default.
{
"user-agent": ""
}
Sadly, that makes it easy for websites to detect and block your scraper. The good news is you can avoid detection by customizing the User-Agent header in your HttpClient requests to mimic real user behavior. Let's see how.
Skip the blocks. Try Zenrows free and get clean web data without the anti-bot fight.
How to Set a Custom User Agent in HttpClient
Here's the step-by-step process to set a C# HttpClient User-Agent.
1. Getting Started
Let's start with a starting script that makes an HTTP request to a target website and retrieves its HTML content.
We created an HttpClient instance, used to make a GET request to httpbin (an API that returns the web client's User Agent string), which retrieves and prints its HTML content.
using System;
using System.Net.Http;
class Program
{
static async Task Main()
{
// Create an instance of HttpClient
HttpClient httpClient = new HttpClient();
// Make a GET request to httpbin.io/user-agent
HttpResponseMessage response = await httpClient.GetAsync("https://httpbin.io/user-agent");
// Read and print the content
string content = await response.Content.ReadAsStringAsync();
Console.WriteLine(content);
}
}
The result should be your current, empty, User Agent.
{
"user-agent": ""
}
Info
If you'd like to review your web scraping fundamentals, check out our C# web scraping guide.
2. Customize UA
The DefaultRequestHeaders property in HttpClient allows you to set a custom User Agent using the `Add()` method, as in the code snippet below. We'll use the real UA you saw earlier.
string customUserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36";
httpClient.DefaultRequestHeaders.Add("User-Agent", customUserAgent);
Now, set a custom User Agent in the HTTP request script we created earlier, and you'll have the following complete code.
using System;
using System.Net.Http;
class Program
{
static async Task Main()
{
// Create an instance of HttpClient
HttpClient httpClient = new HttpClient();
// Set custom User Agent
string customUserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36";
httpClient.DefaultRequestHeaders.Add("User-Agent", customUserAgent);
// Make a GET request to httpbin.io/user-agent
HttpResponseMessage response = await httpClient.GetAsync("https://httpbin.io/user-agent");
// Read and print the content
string content = await response.Content.ReadAsStringAsync();
Console.WriteLine(content);
}
}
Run the code, and your response should be the predefined custom User Agent.
{
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
}
Congrats! You've set an HttpClient User Agent in C#.
However, with a single UA, websites can still easily detect your scraper. Therefore, you must rotate the string to get the best results. Let's see how.
3. Use a Random User Agent in HttpClient
Rotating the HttpClient User-Agent in C# is critical to avoid getting blocked while web scraping, as too many requests from the same User-Agent can be flagged as suspicious activity. You must randomize your User Agent to mimic being different users, making it difficult for websites to detect your scraping activities.
To rotate your UA, start by defining a list of them. For this tutorial, we've taken a few from our list of top User Agents for web scraping.
using System;
using System.Net.Http;
class Program
{
static async Task Main()
{
// Create an instance of HttpClient
HttpClient httpClient = new HttpClient();
// Define your User Agent List
List<string> userAgents = new List<string>
{
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
};
//..
}
}
Next, generate a random index and use it to select a User Agent from your list.
//..
//..
// Generate a random index
var random = new Random();
int randomIndex = random.Next(userAgents.Count);
// Select a random UA using the randomIndex
string randomUserAgent = userAgents[randomIndex];
After that, set the selected UA using the DefaultRequestHeaders class, make a GET request and print the response (like in step 2). You should have the following complete code.
using System;
using System.Net.Http;
class Program
{
static async Task Main()
{
// Create an instance of HttpClient
HttpClient httpClient = new HttpClient();
// Define your User Agent List
List<string> userAgents = new List<string>
{
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36",
};
// Generate a random index
var random = new Random();
int randomIndex = random.Next(userAgents.Count);
// Select a random UA using the randomIndex
string randomUserAgent = userAgents[randomIndex];
// Set selected User Agent
httpClient.DefaultRequestHeaders.Add("User-Agent", randomUserAgent);
// Make a GET request to httpbin.io/user-agent
HttpResponseMessage response = await httpClient.GetAsync("https://httpbin.io/user-agent");
// Read and print the content
string content = await response.Content.ReadAsStringAsync();
Console.WriteLine(content);
}
}
Every time you run the script, a different UA will be used to make your request. For example, here are our results for three requests:
{
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
{
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
{
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
Awesome! You've successfully rotated your User Agent in HttpClient.
Since you'll need to expand your list, it's important to pay attention to your UA construction. For example, if the User-Agent suggests a specific browser version that doesn't exist or is outdated, websites can easily detect the discrepancy or increase the level of alert and block your scraper.
That said, maintaining a diverse, well-formed, and up-to-date pool of User Agents can be challenging. But don't worry about that because the next section shows a way to address this difficulty.
How To Rotate HttpClient User Agents at Scale
Creating a good User Agent rotation system is more complex than it looks. Beyond maintaining a list, you need to update browser versions regularly, make sure they match with operating systems, and remove outdated combinations.
Plus, websites check more than just User Agents to spot bots. They analyze your request timing, network patterns, connection details, and more. Even with perfect User Agent rotation in HttpClient, your requests might still get blocked.
A simpler and more effective solution is to use ZenRows' Universal Scraper API, It provides auto-rotating up-to-date User Agents, premium proxy, JavaScript rendering, CAPTCHA auto-bypass, and everything you need to avoid getting blocked.
Let's see how ZenRows performs against a protected page like the Antibot Challenge page.
Start by signing up for a new account, and you'll get to the Request Builder.
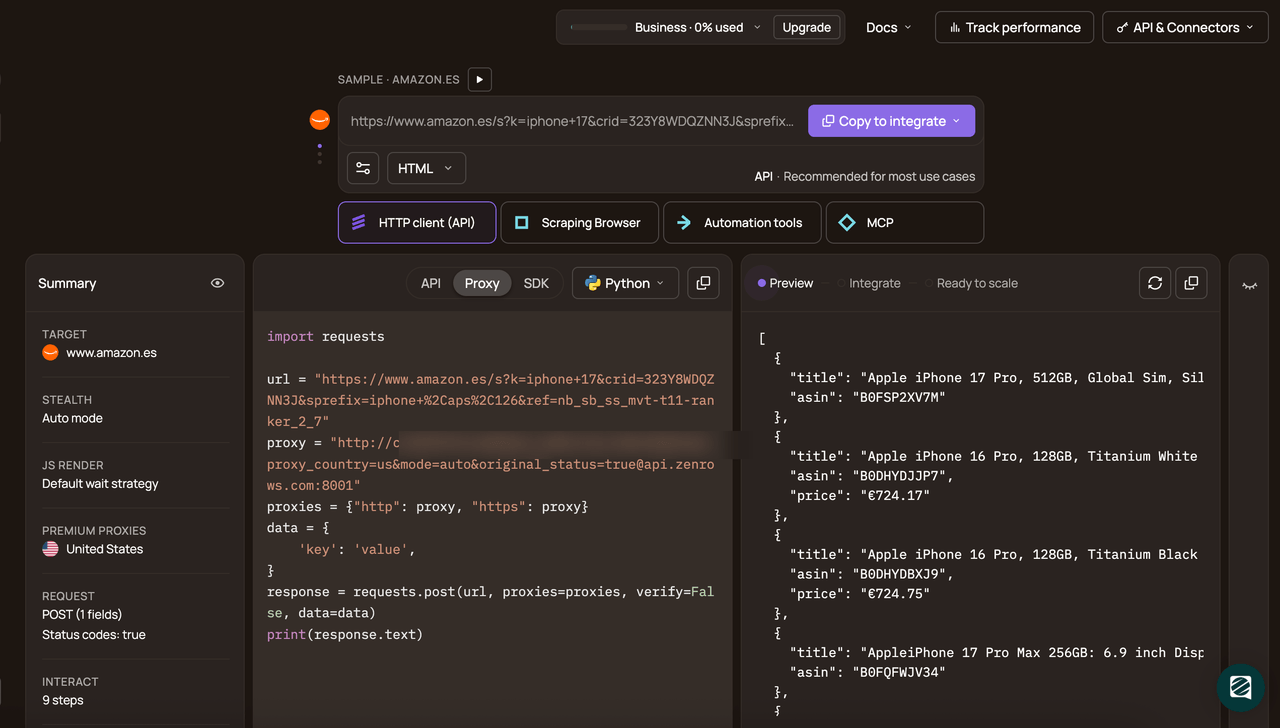
Place the URL, turn on JS Rendering, and activate Premium Proxies.
Next, select C# as your preferred programming language and click on the API connection mode. Then, copy the generated code and paste it into your script.
using RestSharp;
namespace TestApplication {
class Test {
static void Main(string[] args) {
var client = new RestClient("https://api.zenrows.com/v1/?apikey=<YOUR_ZENROWS_API_KEY>&url=https%3A%2F%2Fwww.scrapingcourse.com%2Fantibot-challenge&js_render=true&premium_proxy=true");
var request = new RestRequest();
var response = client.Get(request);
Console.WriteLine(response.Content);
}
}
}
When you run this code, you'll successfully access the page:
<html lang="en">
<head>
<!-- ... -->
<title>Antibot Challenge - ScrapingCourse.com</title>
<!-- ... -->
</head>
<body>
<!-- ... -->
<h2>
You bypassed the Antibot challenge! :D
</h2>
<!-- other content omitted for brevity -->
</body>
</html>
Congratulations! 🎉 You’ve successfully bypassed the Antibot Challenge page using ZenRows. This method works on any website protected by anti-bot systems.
Conclusion
This guide has shown you key points about User Agents in HttpClient:
- What User Agents are and why they matter.
- How to set custom User Agents in your requests.
- Ways to rotate between different User Agents.
- Why User Agent management isn't enough by itself.
Remember that websites use many techniques to detect automation. Instead of managing everything yourself, use ZenRows to make sure you extract all the data you need without getting blocked. Try ZenRows for free!