Does your Ruby Selenium web scraper get blocked by CAPTCHA? No worries: You're about to learn how to solve this problem.
In this article, you'll learn the two methods to bypass CAPTCHA while scraping with Selenium in Ruby:
Can Selenium Ruby Bypass CAPTCHA?
The short answer is yes, but you need to give your Ruby Selenium web scraper a boost.
There are two ways to handle CAPTCHAs when scraping with Ruby:
- Solve the CAPTCHA after it appears.
- Bypass the CAPTCHA so it's not triggered.
The most effective option is to bypass the CAPTCHA and prevent it from appearing. CAPTCHAs that have already been displayed are harder to overcome since a human must solve them.
In this tutorial, we'll focus on CAPTCHA bypass and show you two methods of doing it: a free one and a paid but foolproof one. Let's go!
Method #1: Use Undetected ChromeDriver With Selenium and Ruby
The Undetected ChromeDriver is an optimized version of the Selenium ChromeDriver designed to avoid anti-bots. Although it's dedicated to Python, you can use it in Ruby by porting its executable file to the Selenium service package. To do that, you need a bit of Python knowledge.
The idea is to create an executable file of the Undetected ChromeDriver with Python and use it to run the Selenium ChromeDriver in Ruby.
Let's bypass a simple Turnstile CAPTCHA on nowsecure.nl to see how this method works.
Here's what the target website looks like:

To begin, create an Undetected ChromeDriver executable file with Python. Ensure you've installed the Python library using pip:
pip install undetected-chromedriver
Create a Python file in your code editor and input the following code:
# import the required modules
import undetected_chromedriver as uc
from multiprocessing import freeze_support
if __name__ == '__main__':
# call freeze support to ensure the creation of an executable
freeze_support()
# create a ChromeDriver instance
driver = uc.Chrome(headless=False, use_subprocess=False)
# quit the driver
driver.quit()
Run that code with this command:
python scraper.py
The command will create a new Undetected ChromeDriver executable file in the following directory (for Windows). If you can't find the AppData folder, it may be hidden on your computer. Ensure you enable the option to show files and folders in C:\Users\<YOUR_USERNAME>.
C:/Users/<YOUR_USERNAME>/AppData/Roaming/undetected_chromedriver/undetected_chromedriver.exe
The path might be different on your machine but should default to ...AppData/Roaming/. An equivalent of that directory on Linux should be:
~/.local/share/undetected_chromedriver/undetected_chromedriver
Now, let's bypass the CAPTCHA with the Undetected ChromeDriver in Ruby.
Locate your Chrome browser path, as you'll also use that in your scraper. It should default to the following directory on Windows:
C:/Program Files/Google/Chrome/Application/chrome.exe
The default Chrome path on Linux should be:
~/.config/google-chrome
Import Selenium WebDriver. Then, specify the paths to your Chrome browser and the Undetected ChromDriver executable paths.
# import the required Gem
require 'selenium-webdriver'
# set the path to your actual Chrome browser executable file
chrome_exe_path = 'C:/Program Files/Google/Chrome/Application/chrome.exe'
# set the path to the undetected_chromedriver executable file
undetected_chromedriver_path = 'C:/Users/<YOUR_USERNAME>/AppData/Roaming/undetected_chromedriver/undetected_chromedriver.exe'
Add the Chrome installation path to the Selenium Chrome options. Configure the ChromeDriver service using the Undetected ChromeDriver by pointing to its executable path. Create a driver instance that includes the Chrome options and service settings:
# ...
# set Chrome options
options = Selenium::WebDriver::Chrome::Options.new
options.add_argument('--headless')
options.binary = chrome_exe_path
# configure ChromeDriver service with the specified path
service = Selenium::WebDriver::Service.chrome(path: undetected_chromedriver_path)
# create a new WebDriver instance
driver = Selenium::WebDriver.for :chrome, options: options, service: service
Open the protected web page and add a sleep function to allow your scraper some time to bypass the Turnstile CAPTCHA. Finally, grab a screenshot of the web page to see if you've bypassed the CAPTCHA:
# ...
# navigate to a website
begin
driver.navigate.to 'https://nowsecure.nl'
# allow Undetected ChromeDriver some time to bypass the Turnstile challenge
sleep(10)
# take a screenshot to see if you passed
driver.save_screenshot('nowsecure_screenshot.png')
puts 'Screenshot saved.png'
ensure
# close the driver instance
driver.quit
end
You'll get the following code after combining all the snippets:
# import the required Gem
require 'selenium-webdriver'
# set the path to your actual Chrome browser executable file
chrome_exe_path = 'C:/Program Files/Google/Chrome/Application/chrome.exe'
# set the path to the undetected_chromedriver executable file
undetected_chromedriver_path = 'C:/Users/<YOUR_USERNAME>/AppData/Roaming/undetected_chromedriver/undetected_chromedriver.exe'
# set Chrome options
options = Selenium::WebDriver::Chrome::Options.new
options.binary = chrome_exe_path
options.add_argument('--headless')
# configure ChromeDriver service with the specified path
service = Selenium::WebDriver::Service.chrome(path: undetected_chromedriver_path)
# create a new WebDriver instance
driver = Selenium::WebDriver.for :chrome, options: options, service: service
# navigate to a website
begin
driver.navigate.to 'https://nowsecure.nl'
# allow Undetected ChromeDriver some time to bypass the Turnstile challenge
sleep(10)
# take a screenshot to see if you passed
driver.save_screenshot('nowsecure_screenshot.png')
puts 'Screenshot saved.png'
ensure
# close the driver instance
driver.quit
end
Run the code to bypass CAPTCHA. Here's the generated screenshot, showing a success message in the Turnstile iframe:

You've just bypassed CAPTCHA with Selenium's Undetected ChromeDriver in Ruby.
However, the Undetected ChromeDriver won't bypass advanced anti-bots like Cloudflare, Akamai, and DataDome.
Let's try to access the Cloudflare-protected G2 Reviews website to prove it. Replace the target URL in the previous code with G2's URL.
You'll see that it blocks your scraper with the following message:
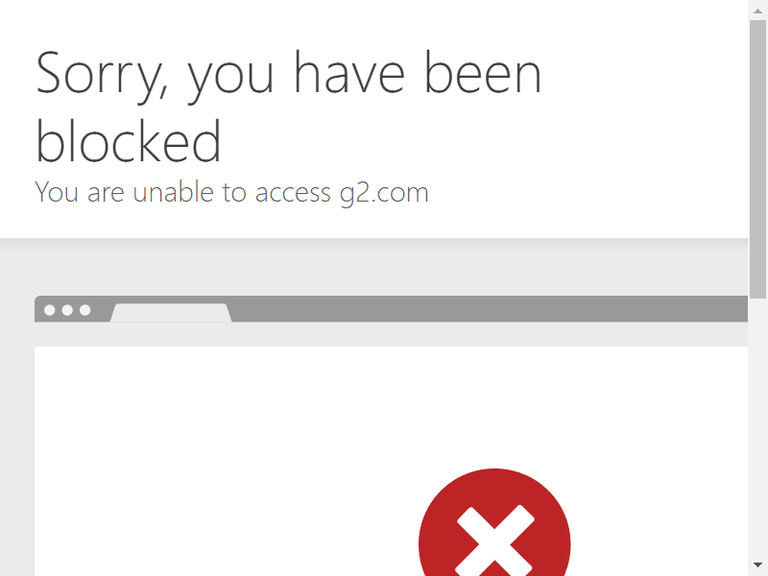
However, there are solutions to bypass even the most advanced anti-bot solutions. Keep reading!
Method #2: Bypass CAPTCHA With a Web Scraping API
CAPTCHAs and anti-bots like Cloudflare will block most free open-source solutions. That's because most complex anti-bots use advanced bot detection mechanisms such as browser fingerprinting and machine learning, which free bypass solutions can't cope with.
The best way to bypass any CAPTCHA is via a web scraping API like ZenRows. It provides a full-fledged anti-bot bypass toolkit, such as JavaScript rendering capabilities, CAPTCHA bypass, automatic header management, premium proxy rotation, and more.
With ZenRows, you'll never get blocked when web scraping again.
Getting started with ZenRows is extremely easy. Let's see how it works against the anti-bot challenge page, a webpage protected by an anti-bot.
Start by signing up for a new account, and you'll get to the Request Builder page. Paste your target URL in the link box, and activate Premium Proxies and JS Rendering.

Select your programming language (Ruby, in this case) and choose the API connection mode. Then, copy and paste the generated code into your scraper file.
Here's what the generated Ruby code looks like:
# gem install faraday
require 'faraday'
url = URI.parse('https://api.zenrows.com/v1/?apikey=<YOUR_ZENROWS_API_KEY>&url=https%3A%2F%2Fwww.scrapingcourse.com%2Fantibot-challenge&js_render=true&premium_proxy=true')
conn = Faraday.new()
conn.options.timeout = 180
res = conn.get(url, nil, nil)
print(res.body)
The above code outputs the protected site's full-page HTML, showing that it bypassed the anti-bot measure:
<html lang="en">
<head>
<!-- ... -->
<title>Antibot Challenge - ScrapingCourse.com</title>
<!-- ... -->
</head>
<body>
<!-- ... -->
<h2>
You bypassed the Antibot challenge! :D
</h2>
<!-- other content omitted for brevity -->
</body>
</html>
Congratulations 🎉! You bypassed anti-bot protection using ZenRows.
Conclusion
You've learned the two ways to handle CAPTCHAs while scraping with Selenium in Ruby. While both methods will work for some anti-bot systems, the recommended approach is using the web scraping API. This solution will let your scraper work uninterrupted, ensuring you can scrape all the data you need without worrying about extra setups, language limitations, and bottlenecks caused by failed requests.
The best web scraping API that guarantees success is ZenRows, an all-in-one content extraction toolkit for scraping any website, regardless of its protection level. Try ZenRows for free!