HTML Agility Pack: How to Parse Data (Tutorial 2026)
Learn how to use HTML Agility Pack in C# to parse the data you want to extract from web pages. Follow this step-by-step tutorial.
HTML Agility Pack ranks among the most popular C# scraping libraries to extract content from HTML by traversing the DOM. In this tutorial, you'll start with the basics and then dig into more complex use cases backed by real-world examples.
You'll learn:
Let's dive in!
What Is HTML Agility Pack?
HTML Agility Pack (HAP) is a library for parsing and manipulating HTML documents in C#. Powered by the Entity Framework Extensions, it provides an agile API with XPath support to read/write the DOM. This makes it a great ally for performing web scraping in C#.
The library is available through the HtmlAgilityPack NuGet package. Add it to your project's dependencies with the command below:
dotnet add package HtmlAgilityPack
Skip the blocks. Try Zenrows free and get clean web data without the anti-bot fight.
How to Parse HTML in C# Using HtmlAgilityPack?
You're about to take your first steps with HtmlAgilityPack in .NET. The target site will be ScrapingCourse.com, an e-commerce site with a paginated list of products. The goal is to extract data from each product on the page:
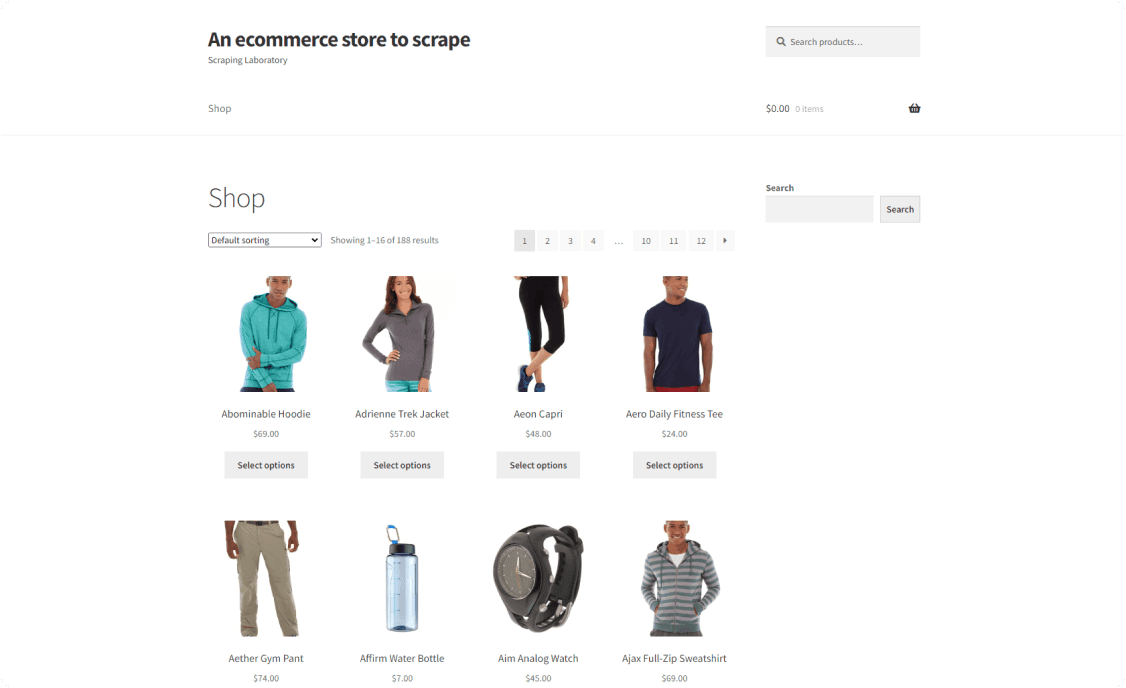
Follow the steps below to learn how to use HTML Agility Pack!
Step 1: Get the HTML Before the Parsing
The first step is to download the HTML content associated with the target page with a web scraper. We'll use HtmlWeb, the HTTP client built into HtmlAgilityPack, but any other HTTP client will do.
Below, the Load() method retrieves the HTML document by making a GET request to the URL passed as a parameter. document.DocumentNode represents the root node of the HTML document and exposes all the HTML Agility Pack features for node selection and data extraction.
using HtmlAgilityPack;
public class Program
{
public static void Main()
{
// initialize the HAP HTTP client
var web = new HtmlWeb();
// connect to target page
var document = web.Load("https://www.scrapingcourse.com/ecommerce/");
// print the raw HTML as a string
Console.WriteLine(document.DocumentNode.OuterHtml);
// scraping logic...
}
}
Execute the script, and it'll produce the following output:
<!DOCTYPE html>
<html lang="en-US">
<head>
<!--- ... --->
<title>Ecommerce Test Site to Learn Web Scraping – ScrapingCourse.com</title>
<!--- ... --->
</head>
<body class="home archive ...">
<p class="woocommerce-result-count">Showing 1–16 of 188 results</p>
<ul class="products columns-4">
<!--- ... --->
</ul>
</body>
</html>
That's the HTML content of the target page, which means that the GET request worked as expected. Great!
At the same time, don't forget that ScrapingCourse.com is nothing more than a scraping sandbox. Most real-world sites use anti-bot measures like Cloudflare, DataDome, Akamai, etc., to detect and block automated requests. In such a scenario, the requests made by your scraper would fail.
How to avoid that? Use ZenRows' API to bypass all anti-scraping systems and get the HTML content of any web page. Then, feed it to HAP or any other HTML parsing technology to start extracting data from it.
Step 2: Extract a Single Element
HTML Agility Pack exposes two methods to select elements on an HTML document:
SelectNodes()returns the HTML nodes matching the XPath expression passed as a parameter.SelectSingleNode()finds the first element that matches the XPath expression given as input.
By default, node selection in HAP relies on XPath. If you're not familiar with it, check out our XPath web scraping guide.
In case you'd prefer to use CSS selectors, you must install the HtmlAgilityPack.CssSelector package. It extends the document.DocumentNode object with two more methods:
QuerySelectorAll()to find all nodes matching the input CSS selector.QuerySelector()to get the first HTML node that matches the CSS selector passed as an argument.
As HAP natively supports XPath expressions, you should prefer them over CSS selectors. But if yon't know which element selection language is best for you, read our comparison article on XPath vs CSS selector.
Let's now use XPath to select the <title> element and then print its content:
// retrieve the "<title>" element
var titleElement = document.DocumentNode.SelectSingleNode("//title");
// extract the inner text from it and print it
var title = HtmlEntity.DeEntitize(titleElement.InnerText);
Console.WriteLine(title);
HtmlEntity.DeEntitize() replaces known HTML entities with their character representations. As a best practice, you should call it every time you access the text of a node with the InnerText attribute.
The above snippet will print the following line:
Ecommerce Test Site to Learn Web Scraping – ScrapingCourse.com
Perfect!
Step 3: Extract Multiple Elements
It's now time to use what you just learned to extract the name, price, and image data from a product HTML element.
Inspect the target element to figure out how to define the node selection strategy. Open ScrapingCourse.com in the browser, right-click on the first product HTML node, and select the "Inspect" option:
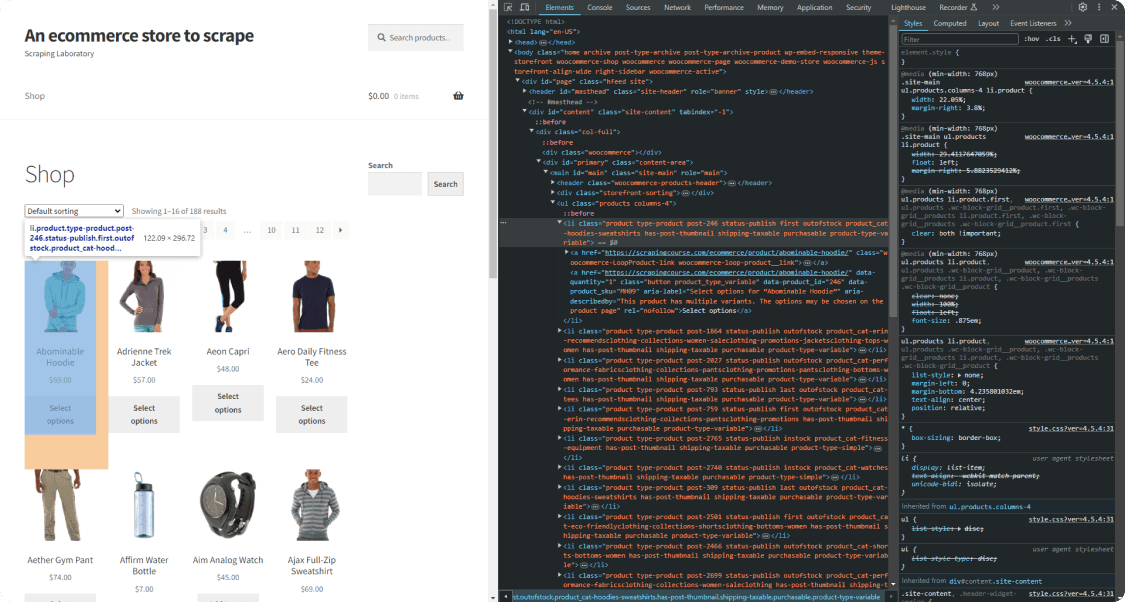
Explore the HTML code and note that the product is a <li> element with a product class. That means you can select it with this XPath expression:
//li[contains(@class, 'product')]
Pass it to SelectSingleNode() to get the first product HTML element on the page:
var productHTMLElement = document.DocumentNode.SelectSingleNode("//li[contains(@class, 'product')]");
Given a product, focus on its inner HTML code and note that the name is in an <h2>, the image in an <img>, and the price in a <span>. Select those elements and extract data from them with this code:
var name = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//h2").InnerText);
var image = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//img").Attributes["src"].Value);
var price = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//span").InnerText);
Attributes gives you access to the collection of HTML attributes of the current node. After selecting one, access its value with the Value property.
Your current scraper will contain the following:
using HtmlAgilityPack;
public class Program
{
public static void Main()
{
// initialize the HAP HTTP client
var web = new HtmlWeb();
// connect to target page
var document = web.Load("https://www.scrapingcourse.com/ecommerce/");
// get the list of HTML product nodes
var productHTMLElement = document.DocumentNode.SelectNodes("//li[contains(@class, 'product')]");
// data extraction logic
var name = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//h2").InnerText);
var image = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//img").Attributes["src"].Value);
var price = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//span").InnerText);
// print the scraped data
Console.WriteLine($"{{ Name = {name}, Image = {image}, Price = {price} }}");
}
}
Run the HTML Agility Pack script, and you'll see the following in the terminal:
{
Name = Abominable Hoodie,
Image = https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh09-blue_main-324x324.jpg,
Price = $69.00
}
Awesome, you just learned how to parse data from a single HTML element!
Step 4: Extract All Matching Elements from a Page
You know how to extract data from a single product now, but the destination page contains more. Retrieve them all with SelectNodes(), which returns an array of HAP HTML elements. Next, iterate over the products in a foreach cycle and apply the data extraction logic on each of them:
var productHTMLElements = document.DocumentNode.SelectNodes("//li[contains(@class, 'product')]");
foreach (var productHTMLElement in productHTMLElements)
{
var name = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//h2").InnerText);
var image = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//img").Attributes["src"].Value);
var price = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//span").InnerText);
}
Put it all together, and you'll get the scraper below:
using HtmlAgilityPack;
public class Program
{
public static void Main()
{
// initialize the HAP HTTP client
var web = new HtmlWeb();
// connect to target page
var document = web.Load("https://www.scrapingcourse.com/ecommerce/");
// get the list of HTML product nodes
var productHTMLElements = document.DocumentNode.SelectNodes("//li[contains(@class, 'product')]");
// iterate over the list of product HTML elements
foreach (var productHTMLElement in productHTMLElements)
{
// data extraction logic
var name = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//h2").InnerText);
var image = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//img").Attributes["src"].Value);
var price = HtmlEntity.DeEntitize(productHTMLElement.SelectSingleNode(".//span").InnerText);
// print the scraped data
Console.WriteLine($"{{ Name = {name}, Image = {image}, Price = {price} }}");
}
}
}
Execute it to get the below output:
{
Name = Abominable Hoodie,
Image = https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh09-blue_main-324x324.jpg,
Price = $69.00
}
// other products omitted for brevity...
{
Name = Artemis Running Short,
Image = https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wsh04-black_main-324x324.jpg,
Price = $45.00
}
Et voilà! You learned how to use HTML Agility Pack to extract all data from a single product page.
Step 5: Extract Data from Different Pages
The target site contains several product pages. To scrape them all, you need to introduce web crawling logic into the script. For a step-by-step tutorial on how to do that, see our guide to web crawling in C#.
Examples of Extracting Specific Data
See the below HAP examples to tackle some of the most common data scraping use cases.
Find Elements By Attribute
Focusing on HTML attributes is a great way to select nodes on a page. In HAP, you have two approaches to achieve that.
Suppose your target page has many .book elements with custom HTML attributes, as in the snippet below. Your goal is to get only the ones whose data-genre attribute has the value "novel".
<div class="book" data-genre="novel">Book 1</div>
<div class="book" data-genre="fiction">Book 2</div>
<div class="book" data-genre="novel">Book 3</div>
<div class="book">Book 4</div>
The first approach involves selecting all .book nodes. Next, you need to reduce the set of matching elements to those that have the desired attribute value. Use the Where() method offered by C# collections to apply the filtering logic:
// get all nodes whose class is "book"
var bookHTMLElements = document.DocumentNode.SelectNodes("//*[contains(@class, 'book')]");
// get all nodes that have the "data-genre" attribute
// and whose value is "novel"
var novelHTMLElements = bookHTMLElements.Where(
e => e.Attributes.Contains("data-genre") &&
e.Attributes["data-genre"].Value == "novel"
).ToList();
The second approach is equivalent and relies on an advanced XPath expression:
var novelHTMLElements = document.DocumentNode.SelectNodes("//*[@data-genre='novel']");
Both methods will produce the same result.
Get All Links
Retrieving all the links on a page is crucial for performing web crawling. You can read our comparison to find out the main differences between web crawling vs web scraping.
Retrieve all <a> nodes and then use Select() to convert them to a list of URL strings.
var linkElements = document.DocumentNode
.SelectNodes("//a")
.Select(a => a.Attributes["href"].Value)
.ToList();
The resulting list will contain also anchor and relative links. If you want to filter them out and get only absolute links, do the following. This gets all links that start with "https":
var absoluteLinkElements = document.DocumentNode
.SelectNodes("//a")
.Where(a => a.Attributes.Contains("href") && a.Attributes["href"].Value.StartsWith("https"))
.Select(a => a.Attributes["href"].Value)
.ToList();
Scrape a List
Using HTML Agility Pack to retrieve data from an HTML list is a popular web scraping scenario. Assume your target page involves this <ul> list:
<ul class="item-list">
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
The goal is to collect the name of each element in the list and store it in a C# array. This takes only a few lines of code:
// initialize a list to store the scraped strings
List<string> items = new List<string>();
// select the list items
var listItemElements = document.DocumentNode.SelectNodes("//ul[@class='item-list']/li");
// populate the "items" list with the desired data
foreach (var listItemElement in listItemElements)
{
items.Add(listItemElement.InnerText);
}
At the end of the foreach loop, items will contain: "Item 1", "Item2", "Item 3".
Find Nodes By Text
Sometimes, defining an effective strategy for selectors isn't easy or even possible. In those scenarios, a practical solution is to search for elements based on their inner text.
Suppose you want to find all the CTA HTML elements that contain the "Add to basket" message. You can retrieve them all with an XPath expression as below:
var ctaElements = document.DocumentNode.SelectNodes("//*[contains(text(), 'Add to basket')]");
This instruction returns the HTML nodes that wrap the "Add to basket" string, not the text nodes.
Retrieve Data From a Table
Scraping HTML tables is probably one of the most common tasks in web scraping with HTML Agility Pack. Take a look at the below table, for example:
<table class="episodes">
<thead>
<tr>
<th>Number</th>
<th>Title</th>
<th>Description</th>
<th>Date</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>Episode 1</td>
<td>Description of Episode 1</td>
<td>2023-01-01</td>
</tr>
<tr>
<td>2</td>
<td>Episode 2</td>
<td>Description of Episode 2</td>
<td>2023-02-01</td>
</tr>
<!-- Other rows... -->
</tbody>
</table>
An effective approach for the snippet below involves the following steps:
- Define a custom object that matches the structure of the data within the table columns. For example:
public class Episode
{
public string Number { get; set; }
public string Title { get; set; }
public string Description { get; set; }
public string Date { get; set; }
}
- Initialize a list to store each row's data from the table.
- Use an XPath selector in HTML Agility Pack to select each row in the table.
- Iterate through each column in the current row by selecting the
<td>elements. - Use a
switchstatement based on the column index to identify the current column. - Get the data from the column and assign it to the corresponding property of the custom object.
- Add the custom object to the list.
The code snippet below implements this algorithm for extracting data from a table that lists episodes of a TV series:
var episodes = new List<Episode>();
// iterate over each row in the table
foreach (var row in document.DocumentNode.SelectNodes("//table[contains(@class, 'episodes')]/tr"))
{
// initialize the custom scraping data object
Episode episode = new Episode();
int col = 0;
// iterate over each column in the row
foreach (var cell in row.SelectNodes("td"))
{
// populate the scraping object
// based on the column index
switch (col)
{
case 0:
episode.Number = cell.InnerText;
break;
case 1:
episode.Title = cell.InnerText;
break;
case 2:
episode.Description = cell.InnerText;
break;
case 3:
episode.Date = cell.InnerText;
break;
}
col++;
}
// add the custom object to the list
episodes.Add(episode);
}
Render JavaScript with HTML Agility Pack
Some web pages rely on JavaScript execution for dynamic data retrieval or rendering purposes. Take, for instance, the infinite scrolling demo below. That page makes new AJAX calls in the browser as the user scrolls down, loading new products. That's a pretty popular mobile interaction or found on social media feeds.
To simulate such interaction and scrape data from the page, you need a tool that can interpret and run JavaScript. However, an HTML parser like HtmlAgilityPack can't do that.
Since only browsers can execute JavaScript, you need a headless browser library to do web scraping. The most used one in C# with this capability is PuppeteerSharp. For other options, explore our guide on the best C# headless browsers.
To scrape data from a dynamic-content page in .NET, start by installing the PuppeteerSharp package:
dotnet add package PuppeteerSharp
Then, use it to perform the infinite scrolling interaction and scrape name and price from each product on the page:
using PuppeteerSharp;
using System.Globalization;
public class Product
{
public string? Name { get; set; }
public string? Price { get; set; }
}
class Program
{
static async Task Main(string[] args)
{
// to store the scraped data
var products = new List<Product>();
// download the browser executable
await new BrowserFetcher().DownloadAsync();
// browser execution configs
var launchOptions = new LaunchOptions
{
Headless = true, // = false for testing
};
// open a new page in the controlled browser
using (var browser = await Puppeteer.LaunchAsync(launchOptions))
using (var page = await browser.NewPageAsync())
{
// visit the target page
await page.GoToAsync("https://scrapingclub.com/exercise/list_infinite_scroll/");
// deal with infinite scrolling
var jsScrollScript = @"
const scrolls = 10
let scrollCount = 0
// scroll down and then wait for 0.5s
const scrollInterval = setInterval(() => {
window.scrollTo(0, document.body.scrollHeight)
scrollCount++
if (scrollCount === numScrolls) {
clearInterval(scrollInterval)
}
}, 500)
";
await page.EvaluateExpressionAsync(jsScrollScript);
// wait for 10 seconds for the products to load
await page.WaitForTimeoutAsync(10000);
// select all product HTML elements
var productElements = await page.QuerySelectorAllAsync(".post");
// iterate over them and extract the desired data
foreach (var productElement in productElements)
{
// select the name and price elements
var nameElement = await productElement.QuerySelectorAsync("h4");
var priceElement = await productElement.QuerySelectorAsync("h5");
// extract their text
var name = (await nameElement.GetPropertyAsync("innerText")).RemoteObject.Value.ToString();
var price = (await priceElement.GetPropertyAsync("innerText")).RemoteObject.Value.ToString();
// instantiate a new product and add it to the list
var product = new Product { Name = name, Price = price };
products.Add(product);
}
}
}
}
To better understand how that script works, check out our in-depth PuppeteerSharp tutorial.
Alternatively, the best tool for JavaScript rendering in C# is ZenRows. It's a web scraping API that offers headless browser functionality, easily integrates with HtmlAgilityPack, and equips you with a complete toolkit to avoid getting blocked when web scraping.
Extra Capabilities of HTML Agility Pack
In this Html Agility Pack tutorial, we've explored some of the most common data parsing scenarios. Yet, HAP has much more to offer, and there are a few features you should know about:
| Feature | Used For | Code Example |
|---|---|---|
Load() |
Load HTML from a file | var document = new HtmlDocument(); document.Load("index.html"); |
LoadHtml() |
Load HTML from a string | var document = new HtmlDocument(); document.LoadHtml(@"<html><heads>..."); |
Ancestors() |
Get all the ancestors of the current node | var ancestors = currentNode.Ancestors(); |
Descendants() |
Get all descendant nodes in an enumerated list | var descendants = currentNode.Descendants(); |
NextSibling |
A property to get the HTML node immediately following the current element | nextNode = currentNode.NextSibling; |
WriteTo() |
Save the current node to a string | var nodeString = node.WriteTo(); |
AppendChild() |
Add a node to the end of the list of children of the current node | var h1Node = HtmlNode.CreateNode("<h1>This is an h1 heading</h1>");currentNode.AppendChild(h1Node); |
InsertAfter() |
Insert a node immediately after the specified reference node | htmlBody.InsertAfter(newNode, refNode); |
Remove() |
Remove the current node from the DOM | currentNode.Remove(); |
DetectEncoding() |
Detect the encoding of an HTML file | var detectedEncoding = HtmlDocument.DetectEncoding("index.html); |
Learn more in the official documentation.
Conclusion
In this tutorial for HTML Agility Pack, you learned the fundamentals of parsing HTML documents. You started from the basics and dove into more advanced use cases to become a parsing expert.
Now you know:
- What the HtmlAgilityPack C# library is.
- How to use it to retrieve data from an HTML document.
- How it supports common scraping scenarios.
- The advanced features for DOM manipulation and more.
Yet, no matter how good your web data parser is, performing web scraping without getting blocked isn't easy because anti-bot measures will still catch you. Bypass them all with ZenRows, a web scraping API with headless browser capabilities, IP rotation, and an advanced built-in toolkit to avoid anti-bot systems. Scraping sites is easier now. Try ZenRows for free!
FAQ
Is HTML Agility Pack for Free?
Yes, HTML Agility Pack (HAP) is a free and open-source library distributed under the MIT License. Users can use, modify, and distribute it for free, which makes it a popular choice for parsing HTML documents at no cost.