You can't scrape modern websites without JavaScript execution and ways to mimic natural browsing behavior. Skipping them leads straight to bans and blocks from anti-bots.
For optimal performance, you need a Java headless browser. Headless browsers simulate a real browser environment, enabling you to render dynamic content and solve JavaScript challenges.
However, the headless browser landscape is broad, and not all browsers are equally suited to every use case. To help you choose the best tool for your project, let's explore the top five Java headless browsers for web scraping.
What Is the Best Headless Browser in Java?
The best headless browser choice for web scraping in Java is relative. You should investigate your tool candidates based on speed, ease of use, and the quality of anti-bot bypass and decide on your priorities.
Here's a quick comparison table of all the software reviewed below, highlighting the factors you should take into account.
| Popularity | Ease of Use | Speed | Anti-bot Bypass | |
|---|---|---|---|---|
| ZenRows | Rapidly growing | Beginner-friendly and easy to set up | Fast | Bypasses any anti-bot system, regardless of complexity |
| Selenium | Large user base | Requires additional setup | Can get slow when running multiple instances in parallel | Gets blocked by anti-bot systems |
| HtmlUnit | Rapidly growing | Moderate | Moderate | Gets blocked by anti-bot systems |
| Playwright | Rapidly growing | Moderate | Moderate | Gets blocked by anti-bot systems |
| Jauntium | Relatively small | Uses Selenium and Jaunt, so it requires additional setup | Moderate | Gets blocked by anti-bot systems |
Each tool will be used to scrape the Aeon Capri product page on ScrapingCourse.com, a demo e-commmerce website, to verify its capabilities and demonstrate how it works.

1. ZenRows: The Web Scraping Swiss Knife

ZenRows is a full-package web scraping API. Its headless browser functionality offers full JavaScript support, so you can render dynamic websites like a regular browser. It lets you interact with the page once its content is loaded as well as block resources (stylesheets, images, fonts, scripts, etc.) that delay your HTML responses.
However, ZenRows isn't just an average headless browser. It's an all-in-one solution that lets you bypass any anti-bot system and scrape without getting blocked. With features like premium proxies, CAPTCHA bypass, full header rotation, proxy rotator, and more, the tool allows you to focus on extracting data rather than the complexities of circumventing anti-bot solutions.
👍 Pros:
- Both API and proxy connection.
- Advanced anti-bot bypass features to scrape all web pages.
- Auto-rotating premium proxies.
- Easy-to-use, intuitive API.
- Extensive documentation and a rapidly growing developer community.
👎 Cons:
- Limited customization compared to open-source libraries.
⚙️ Features:
- Premium proxies
- Geolocation
- Custom headers
- JavaScript rendering
- Page interaction
- Block resources
- CSS selectors
- JSON response
- Auto-parsing
- Full page screenshot
- Concurrency headers
👨💻 Example:
Let's scrape the target web page using ZenRows. To get started, sign up to get your free API key.
In your dashboard, paste your target URL (https://www.scrapingcourse.com/ecommerce/product/aeon-capri/) in the Request Builder section, check the box for Premium Proxies, and activate the JavaScript Rendering boost mode to trigger ZenRows headless browser functionality.

Next, inspect the target page in your browser to identify the location of the product's price.

The desired data is located in a span with class amount. Right-click on the span tag and copy its selector.
Head back to your dashboard. Select the CSS Selectors output option at the bottom left, and replace the placeholder code with the selector you copied.
Your output configuration will look like this:
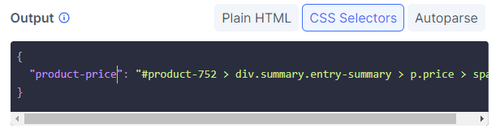
Lastly, select a language (Java), and you'll get your script ready to try.
You'll get the following code:
import org.apache.hc.client5.http.fluent.Request;
public class APIRequest {
public static void main(final String... args) throws Exception {
String apiUrl = "https://api.zenrows.com/v1/?apikey=<YOUR_ZENROWS_API_KEY>&url=https%3A%2F%2Fwww.scrapingcourse.com%2Fecommerce%2Fproduct%2Faeon-capri%2F&css_extractor=%257B%2522summary%2522%253A%2522.summary.entry-summary%2522%257D";
String response = Request.get(apiUrl)
.execute().returnContent().asString();
System.out.println(response);
}
}
Run it, and you'll get the product's price.
{
"product-price": "£37.00"
}
That's how easy it is to scrape with ZenRows.
2. Selenium: Browser-Agnostic Web Automation

Selenium is one of the most popular Java web scraping libraries that offers several features for automating web applications in Chrome, Safari, Edge, Internet Explorer, and Firefox. Its ability to render JavaScript like a regular browser and simulate real-world user interactions makes it a valuable web scraping tool.
Selenium is the most popular headless browser on this list. It's open-source and enjoys an active user base and developer community, guaranteeing many resources for troubleshooting issues and finding solutions.
However, Selenium tends to work slowly compared to other Java headless browsers and requires additional setup. For example, before writing any code, you must install language-specific binding libraries, your browser of choice, and its corresponding driver.
👍 Pros:
- Supports multiple browsers.
- Can run multiple instances in parallel.
- Easy identification of web elements using selectors.
- Supports multiple programming languages.
- Extensive documentation and large developer community.
- Multiple device testing.
- Continuous integration tools.
- Captures screenshots and generates PDFs.
👎 Cons:
- Requires WebDriver configuration and setup for specific browsers.
- Can get slow and resource-intensive, especially when running multiple instances in parallel.
- Its automation properties are easily detectable.
⚙️ Features:
- Page interaction
- Block resources
- Proxy support
- Multi-language compatibility
- Playback and record feature using the Selenium IDE
- Integrates with frameworks like Ant and Maven.
- Supports multiple operating systems.
- Automates form submission, UI testing, keyboard input, etc.
👨💻 Example:
The example below shows how to extract data using Selenium Java.
This code sets up a Selenium Webdriver to work with ChromeDriver by using WebDriverManager to manage the driver executable. It then creates a ChromeDriver instance, which navigates to the target web page and retrieves the product's price.
package com.example;
// import the required dependencies
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.*;
import io.github.bonigarcia.wdm.WebDriverManager;
public class Main {
public static void main(String[] args) {
// set Chrome options for headless mode
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless"); // run in headless mode
WebDriver driver = new ChromeDriver(options);
// navigate to the target website
driver.get("https://www.scrapingcourse.com/ecommerce/product/aeon-capri/");
// retrieve the product's price
WebElement priceElement = driver.findElement(By.cssSelector("#product-2027 > div.summary.entry-summary > p.price > span"));
String price = priceElement.getText();
System.out.println("Product Price: " + price);
// close the browser
driver.quit();
}
}
3. HtmlUnit: Lightweight API

HtmlUnit is an open-source Java headless browser to interact with HTML documents programmatically. Its extensive API can simulate browser behavior, including visiting web pages, filling out forms, clicking links, etc., just like you would in a regular browser.
HtmlUnit continuously improves its JavaScript support. It now lets you handle complex AJAX libraries, making it a good choice for web scraping. It's flexible and can simulate different browsers, including Chrome, Firefox, or Internet Explorer, depending on the configuration settings.
👍 Pros:
- Supports multiple browsers.
- Request headers customization.
- Ability to inject code into an existing web page.
- Page interaction.
- HTML manipulation.
- Growing developer community.
- Can easily be integrated into CI pipelines.
- Captures screenshots and generates PDFs.
👎 Cons:
- Doesn't entirely replicate an actual browser.
- Can easily be detected by anti-bot measures.
⚙️ Features:
- Supports HTTP and HTTPS protocols.
- Error handling flexibility.
- Page interaction.
- Proxy support.
- Basic and NTLM authentication.
- Integrates with testing frameworks.
- Uses the Rhino JavaScript engine.
- Supports multiple operating systems.
👨💻 Example:
The following code creates a WebClient instance, navigates to the target website, and extracts the product's price using HtmlUnit's querySelector method.
package com.example;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomNode;
public class Main {
public static void main(String[] args) {
// create Chrome Web Client instance using specified proxy settings.
try (final WebClient webClient = new WebClient()) {
// disable JavaScript execution
webClient.getOptions().setJavaScriptEnabled(false);
// navigate to target web page
HtmlPage page = webClient.getPage("https://www.scrapingcourse.com/ecommerce/product/aeon-capri/");
// extract product price element using its CSS selector
DomNode priceElement = page.getFirstByXPath("//*[@id=\"product-2027\"]/div[2]/p[1]/span");
String price = priceElement.getTextContent();
System.out.println("Product Price: " + price);
} catch (Exception e) {
e.printStackTrace();
}
}
}
4. Playwright: Microsoft's Unified API

Playwright is an open-source library that offers a single API for automating Chrome, Firefox, and Webkit. You can write code using the same commands, methods, and functions regardless of your browser choice.
Like most solutions on this list, Playwright allows you to interact with a web page like you would using a regular browser. Yet, it supports a few more advanced features, such as network interceptions and auto-wait. Auto-wait enables your script to automatically wait until elements become actionable before it performs actions, eliminating the need for manual timeouts.
Additionally, Playwright supports Trusted Events, which let you interact with dynamic elements like a real user. The tool's selectors can pierce Shadow DOM, granting access to elements that are otherwise hidden from standard DOM traversal methods.
👍 Pros:
- Supports multiple browsers.
- Automatically waits for elements before performing actions.
- Smart assertions that retry until the necessary conditions are met.
- Can run multiple instances in parallel.
- Captures videos and screenshots.
- Page interaction.
- HTML manipulation.
- Extensive documentation and growing developer community.
👎 Cons:
- Can only handle HTTP/HTTPS and browser-specific protocols.
- Limited support for browser extensions.
- The community is not as large as its open-source counterparts (for example, Selenium).
- Can easily be detected by anti-bot measures.
⚙️ Features:
- Cross-browser
- Cross-platform
- Network interception
- State persistence for faster execution
- Page interaction
- Block resources
- Proxy support.
- Supports multiple operating systems
- Automatic waits
👨💻 Example:
The code below launches a Webkit browser, opens a new page, navigates to the target web page, and retrieves the product's price.
package com.example;
// import required library
import com.microsoft.playwright.*;
public class Main {
public static void main(String[] args) {
// initialize Playwright
try (Playwright playwright = Playwright.create()) {
// launch browser
Browser browser = playwright.webkit().launch();
// open a new page
Page page = browser.newPage();
// navigate to target web page
page.navigate("https://www.scrapingcourse.com/ecommerce/product/aeon-capri/");
// extract product price using selector
String price = page.innerText("#product-2027 > div.summary.entry-summary > p.price > span");
System.out.println("Product Price: " + price);
}
}
}
5. Jauntium: The Selenium Jaunt Fusion

Jauntium is a free Java library that merges Selenium's functionalities with Jaunt's user-friendly architecture. This union results in a powerful solution for automating Chrome, Firefox, Safari, Edge, IE, and other modern web browsers.
One of Jauntium's standout features is its support for Regex-enabled DOM querying. With this capability, you can use Regular Expressions (Regex) to select elements within the DOM. It works great for advanced searches.
For example, suppose you want to extract all site links with the word `shops` in their URLs. With regex-enabled querying, you can construct a regular expression pattern that matches that term and use it to select those links.
In addition to Regex DOM querying, Jauntium provides utility classes like Form and Table, which handle forms and extract data from tables.
👍 Pros:
- Supports multiple browsers.
- Page interaction.
- Works with tables and forms.
- Blends Selenium's functionality with Jaunt's user-friendly architecture.
- Supports DOM traversal and manipulation.
- Supports querying with XPath and CSS selectors.
- Fluent DOM navigation and search chaining
👎 Cons:
- Relatively small community and developer user base.
- Requires additional setup like Selenium.
- Can easily be detected by anti-bot measures.
⚙️ Features:
- Cross-browser
- Regex-enabled DOM querying
- Fine-grained DOM access (attributes, nodes, etc.)
- Javascript execution
- File downloading
- CSS selectors
- XPath
- JavaScript Execution
- Web pagination discovery
- Proxy support
👨💻 Example:
The example below shows how to retrieve data with Jauntium.
The code uses Jauntium to launch a headless Chromium browser. It then creates a new page, navigates to the target URL, and extracts the product price using Jauntium's findFirst() method.
package com.example;
// import the required dependencies
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.*;
import com.jauntium.*;
public class Main {
public static void main(String[] args) {
// use WebDriver manager to set up ChromeDriver
WebDriverManager.chromedriver().setup();
// create Chrome options object
ChromeOptions options = new ChromeOptions();
// specify headless mode
options.addArguments("--headless");
try {
// create a new browser window
Browser browser = new Browser(new ChromeDriver(options));
// navigate to target URL
browser.visit("https://www.scrapingcourse.com/ecommerce/product/aeon-capri/");
// extract product price.
Element priceElement = browser.doc.findFirst("<p class=price>");
String price = priceElement.getText();
System.out.println("Product Price: " + price);
browser.quit();
}
// if element isn't found, handle JauntiumException.
catch(JauntiumException e){
System.err.println(e);
}
}
}
Benchmark: Which Browser Is the Fastest?
To gauge the speed and efficiency of each headless browser, we ran a benchmarking experiment.
The test scenario for this benchmark matches the code examples provided earlier. Each tool navigates to ScrapingCourse.com, retrieves its HTML, and extracts the product's price.
The table below shows the result of the test:
| Throughput (Operations per second) | Time Taken (Seconds) | |
|---|---|---|
| ZenRows | 0.322 | 3.10 |
| Selenium | 0.101 | 9.90 |
| HtmlUnit | 0.111 | 9.00 |
| Playwright | 0.109 | 9.17 |
| Jauntium | 0.105 | 9.52 |
As anticipated, ZenRows is the fastest performer, completing the task in 3 seconds. HtmlUnit and Playwright share the distant second position with similar performances of approximately 9 seconds. Jauntium is a close third at 9.5 seconds. Meanwhile, Selenium recorded the slowest time of roughly 10 seconds.
Based on the benchmark results, Zenrows is around 200% faster than HtmlUnit and Playwright, while Selenium and Jauntium are approximately 11% slower than HtmlUnit and Playwright.

To benchmark these libraries, we used Java Microbenchmark Harness, a tool developed to measure the performance of tools by turning methods into benchmarks.
The measurements were made on an AMD Ryzen 9 6900HX with Radeon Graphics, 1 CPU, 16 logical and 8 physical cores, and .NET SDK 8.0.100-rc.2.23502.2. However, the performance should be similar on any machine configuration.
Conclusion
Choosing the right Java headless browser can greatly affect the quality and speed of your project.
While Selenium is the most popular due to its extensive community support, ZenRows is the fastest performer and offers the most complete features for web scraping. It guarantees the most efficient performance and full anti-bot protection, resulting in fast, hassle-free scraping. Try ZenRows with a free trial!