Playwright Stealth: Does It Still Work for Scraping?
Learn how to implement Playwright Stealth to scrape without getting blocked and access the data you want.

The playwright-stealth plugin patches the most obvious fingerprint leaks that make headless Playwright easy to detect. These include signals like navigator.webdriver, the HeadlessChrome User Agent flag, and missing plugin arrays. While the plugin is enough for some targets, it doesn't work for others. Understanding exactly why helps you decide when to use it and when to opt for an alternative solution.
This guide covers the full Playwright Stealth setup in Python and Node.js, walks through what each evasion module actually does, shows you how to test whether it's working, and explains what to do when the stealth plugin alone isn't enough.
What Is Playwright Stealth?
Playwright Stealth is an anti-bot evasion plugin for the Playwright framework. Adapted from puppeteer-extra-plugin-stealth, Playwright Stealth extends Playwright's web scraping functionality by patching the bot-like signals in the standard library.
While web scraping with Playwright provides browser-like functionalities, such as JavaScript rendering, it's still easy for websites to flag your requests as automated. This is due to specific properties unique to headless browsers, such as the headless: true WebDriver navigator field, the HeadlessChrome User Agent flag, missing plugins, and other bot-like signals exposed by browser fingerprinting.
The Playwright Stealth plugin masks the base Playwright version by patching these loopholes. The plugin is available in Node.js and Python. So, you can leverage the stealth functionality in either language.
Why Headless Playwright Gets Detected and What Stealth Fixes
Playwright runs a real Chromium browser in headless mode, but it leaves a set of signals that anti-bot systems check for.
A quick vulnerability check on a test site, such as Sannysoft, reveals the difference between actual browser behavior and Playwright's weaknesses. An actual Chrome browser passes all checks as shown:

However, the base Playwright library fails various fingerprinting tests on the same website by revealing various automation signals.
Try the test with the following basic Playwright script. The script sets up a Chromium instance, opens the target site, and takes a screenshot of the fingerprinting result:
# pip3 install playwright
# playwright install chromium
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as p:
# launch Chromium in headless mode
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# open the target site
await page.goto("https://bot.sannysoft.com/")
await asyncio.sleep(5)
await page.screenshot(path="screenshot.png")
await browser.close()
asyncio.run(main())
The result shows that Playwright fails the fingerprinting test by revealing various automation signals. These include the HeadlessChrome flag in the User Agent, the presence of a WebDriver, failed Chrome runtime and permissions, a missing plugin array, a faulty WebGL Renderer, and more.

The Playwright Stealth plugin patches these leaks by injecting evasion scripts before requests are sent (evaluateOnNewDocument under the hood), making your scraper less detectable. Here are the main ones:
navigator.webdriver: This is the most obvious bot-like signal in any standard automated headless browser. Standard Playwright sets this to true, but the plugin overrides it to undefined, which matches what a real browser returns.- User Agent: Headless Chrome appends
HeadlessChrometo the UA string. The stealth plugin replaces it with the standard Chrome UA for the same version. navigator.pluginsandnavigator.mimeTypes: the standard Playwright returns empty arrays for these fingerprints, but the real Chrome browser has a populated plugins list. Playwright Stealth mocks Chrome's realistic plugin and MIME type entries.chrome.runtime: Thechrome.runtimeobject is either missing completely or exists as an empty array in the standard Playwright version. The stealth plugin patches that object to mimic an actual Chrome environment, even in headless mode. However, this patch is disabled by default in v2.x of the plugin because enabling it causes compatibility issues on some sites. If you're still getting detected and have ruled out other signals, enabling it explicitly is worth testing.navigator.languages: The language array is usually empty in headless mode. The plugin sets it to ['en-US', 'en'] by default, and you can override it.navigator.hardwareConcurrency: The plugin sets this to 4 rather than whatever the underlying host reports, which can itself be a fingerprinting signal.- WebGL renderer: Headless Chrome exposes SwiftShader or Mesa as the GL renderer, which is a strong bot signal. Playwright Stealth attempts to normalize this, but note that hardware-level GL fingerprinting is one of its weak points.
- iframe contentWindow: Some detection scripts check whether
window.topandwindow.frameElementbehave consistently in iframes. The plugin patches this to prevent inconsistencies left by Playwright automation.
Despite covering these major leakage points, playwright-stealth can't address detection that operates outside the browser's JavaScript environment. Examples include TLS fingerprinting (JA3/JA4 hashes), which happens at the network layer before any page code runs, and behavioral analysis, which scores mouse movements, scroll patterns, and click timing and operates at the application layer. These detection layers require an entirely different approach.
Skip the blocks. Try Zenrows free and get clean web data without the anti-bot fight.
How to Web Scrape with Playwright Stealth in Python
Follow the next steps to web scrape using Playwright Stealth in Pythond.
Step 1: Set up Playwright Stealth Plugin in Python
Since Playwright Stealth is only a plugin, it still relies on the standard Playwright automation API. Installing the Playwright Stealth plugin in Python automatically installs Standard Playwright. Install it with pip and download Chromium browser binary using the following commands:
pip3 install playwright-stealth
playwright install chromium
Step 2: Apply the Stealth Plugin
stealth_async(page) and stealth_sync(page) are v1.x patterns of the plugin that no longer work. Version 2.x introduced a context manager API that wraps the Playwright instance rather than individual pages. Using the old pattern with the current package will throw an AttributeError.
Let's try to test the Playwright Stealth plugin on Sannysoft, the previous fingerprint website.
# pip3 install playwright
# playwright install chromium
from playwright.async_api import async_playwright
from playwright_stealth import Stealth
import asyncio
async def main():
# wrap Playwright instance around the stealth plugin
async with Stealth().use_async(async_playwright()) as p:
# launch Chromium in headless mode
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# open the target site
await page.goto("https://bot.sannysoft.com/")
await asyncio.sleep(5)
await page.screenshot(path="screenshot.png")
await browser.close()
asyncio.run(main())
The new result shows that Playwright with the stealth plugin passes the fingerprinting tests that the base Playwright failed earlier. Notably, the previous `HeadlessChrome` User Agent flag has been patched to use real Chrome, WebDriver is now missing, as expected of a real Chrome browser, and WebGL vendor and Renderer are now properly patched to mimic those of an actual Chrome:

Now let's see a minimal Playwright Stealth working example that scrapes the Ecommerce challenge page:
# pip3 install playwright-stealth
# playwright install chromium
import asyncio
from playwright.async_api import async_playwright
from playwright_stealth import Stealth
async def main():
# wrap Playwright instance around the stealth plugin
async with Stealth().use_async(async_playwright()) as p:
# launch Chromium in headless mode
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# open the target site
await page.goto("https://www.scrapingcourse.com/ecommerce/")
# extract data from the site
await page.wait_for_selector("ul.products li.product")
products = await page.evaluate("""() =>
Array.from(document.querySelectorAll("ul.products li.product")).map(item => ({
name: item.querySelector(".woocommerce-loop-product__title")?.innerText.trim(),
price: item.querySelector(".price")?.innerText.trim(),
}))
""")
# collect the scraped data
data = []
for product in products:
data.append({"name": product["name"], "price": product["price"]})
print(data)
await browser.close()
asyncio.run(main())
For cases where you need stealth on a specific browser context rather than the entire Playwright instance, like when running multiple contexts in parallel with different requirements, use apply_stealth_async() directly:
# pip3 install playwright-stealth
# playwright install chromium
import asyncio
from playwright.async_api import async_playwright
from playwright_stealth import Stealth
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
# apply stealth to this context only
context = await browser.new_context()
await Stealth().apply_stealth_async(context)
page = await context.new_page()
await page.goto("https://www.scrapingcourse.com/ecommerce/")
await page.wait_for_selector("ul.products li.product")
products = await page.evaluate("""() =>
Array.from(document.querySelectorAll("ul.products li.product")).map(item => ({
name: item.querySelector(".woocommerce-loop-product__title")?.innerText.trim(),
price: item.querySelector(".price")?.innerText.trim(),
}))
""")
data = []
for product in products:
data.append({"name": product["name"], "price": product["price"]})
print(data)
await browser.close()
asyncio.run(main())
The above code outputs the same result as the initial one that wraps the entire Playwright instance, and evasion modules are still injected before any page code runs. The only difference is that apply_stealth_async() lets you selectively apply stealth to specific contexts while leaving others unpatched. This is useful when your scraper handles a mix of protected and unprotected targets.
Synchronous API
If you're writing a quick script or integrating Playwright into a synchronous codebase, such as a Django view, a Flask endpoint, or a sequential data pipeline. The sync API avoids the async boilerplate without any difference in stealth behavior.
# pip3 install playwright-stealth
# playwright install chromium
import asyncio
from playwright.sync_api import sync_playwright
from playwright_stealth import Stealth, ALL_EVASIONS_DISABLED_KWARGS
import time
def main():
# wrap Playwright instance around the stealth plugin and pass the config
with Stealth().use_sync(sync_playwright()) as p:
# launch Chromium in headless mode
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# open the target site
page.goto("https://www.scrapingcourse.com/ecommerce/")
time.sleep(5)
print(page.content())
browser.close()
main()
Set up Playwright Stealth in Node.js
The Node.js Playwright stealth story is slightly different from Python. It's worth noting that, unlike the Python counterpart, the Node.js version hasn't seen significant maintenance since 2023. It still functions for most purposes, though, but it's worth knowing before you depend on it. That said, the original playwright-extra requires puppeteer-extra-plugin-stealth to work.
Install the dependencies with npm:
npm install playwright playwright-extra puppeteer-extra-plugin-stealth
npx playwright install chromium
The plugin registers globally on the chromium object. So, every browser instance launched through it inherits the stealth patches.
Here's a basic Node.js Playwright Stealth script:
// npm install playwright playwright-extra puppeteer-extra-plugin-stealth
// npx playwright install chromium
const { chromium } = require('playwright-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// initialize the plugin
chromium.use(StealthPlugin());
(async () => {
// launch the browser in headless mode
const browser = await chromium.launch({ headless: true });
const page = await browser.newPage();
// open the target site
await page.goto('https://www.scrapingcourse.com/ecommerce/');
console.log(await page.content());
await browser.close();
})();
Configuring Individual Evasion Modules
If you're testing detection behavior or a particular evasion module conflicts with your target, you can disable specific patches by passing the configuration to the Stealth() class:
In the code below, stealth_config first disables all evasions with ALL_EVASIONS_DISABLED_KWARGS. It then selectively patches navigator.languages, and excludes navigaor.webdriver and navigator.userAgent from the patch:
# pip3 install playwright-stealth
# playwright install chromium
import asyncio
from playwright.async_api import async_playwright
from playwright_stealth import Stealth, ALL_EVASIONS_DISABLED_KWARGS
# configure the patches
stealth_config = {
**ALL_EVASIONS_DISABLED_KWARGS,
"navigator_webdriver": False,
"navigator_user_agent": "False",
"navigator_languages_override": ("en-US", "en"),
"navigator_languages": True,
}
async def main():
# wrap Playwright instance around the stealth plugin and pass the config
async with Stealth(**stealth_config).use_async(async_playwright()) as p:
# launch Chromium in headless mode
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# open the target site
await page.goto("https://bot.sannysoft.com/")
await asyncio.sleep(5)
# take a screenshot
await page.screenshot(path="screenshot.png")
await browser.close()
asyncio.run(main())
The above code outputs the following result, showing the patched language with all other evasions disabled, including navigator.webdriver:
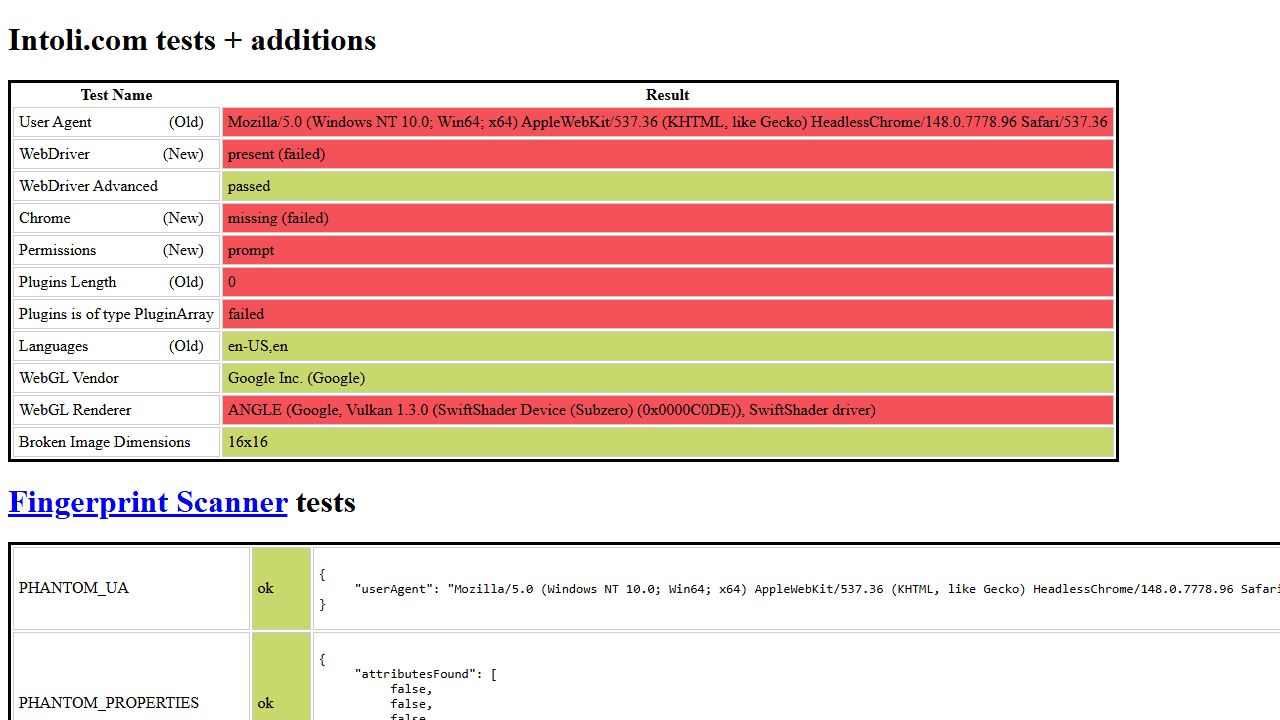
You can also select the parts of Playwright you want to patch in Node.js. For Node.js, any unlisted evasion module not included in the stealth configuration remains unpatched:
// npm install playwright playwright-extra puppeteer-extra-plugin-stealth
// npx playwright install chromium
const { chromium } = require('playwright-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
const stealth_config = new Set([
'chrome.app',
'chrome.csi',
'chrome.loadTimes',
'navigator.webdriver',
'navigator.plugins',
'navigator.languages',
'navigator.permissions',
'navigator.vendor',
'user-agent-override',
'media.codecs',
'iframe.contentWindow',
// evasion modules not included will be disabled
])
// initialize the stealth plugin with the configs
chromium.use(StealthPlugin({enabledEvasions:stealth_config}));
(async () => {
// launch the browser in headless mode
const browser = await chromium.launch({ headless: true });
const page = await browser.newPage();
// open the target site
await page.goto('https://bot.sannysoft.com/');
// take a screenshot
await page.screenshot({ path: "screenshot.png" });
await browser.close();
})();
Limitations of Playwright Stealth and the Solution
While Playwright Stealth is a powerful web scraping plugin, it doesn't work against advanced anti-bot protections.
The stealth plugin still leaves salient loopholes that expose it to detection. While basic anti-bot setups might overlook minor lapses, dedicated ones spot the slightest detail. This makes it unreliable for consistently bypassing anti-bot measures, especially during large-scale scraping.
Additionally, open-source stealth tools often rely on outdated evasion techniques due to limited maintenance. Therefore, they may struggle to keep pace with the more consistently updated anti-bot security measures.
To prove it, let's try to scrape the Antibot Challenge page, which implements advanced anti-bot measures. Simply replace the target URL in the previous Playwright Stealth setup with this new one and run your request:
# pip3 install playwright
# playwright install chromium
from playwright.async_api import async_playwright
from playwright_stealth import Stealth
import asyncio
async def main():
async with Stealth().use_async(async_playwright()) as p:
# launch Chromium in headless mode
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# open the target site
await page.goto("https://www.scrapingcourse.com/antibot-challenge")
await asyncio.sleep(5)
await page.screenshot(path="screenshot_1.png")
await browser.close()
asyncio.run(main())
Playwright Stealth gets blocked, as shown:
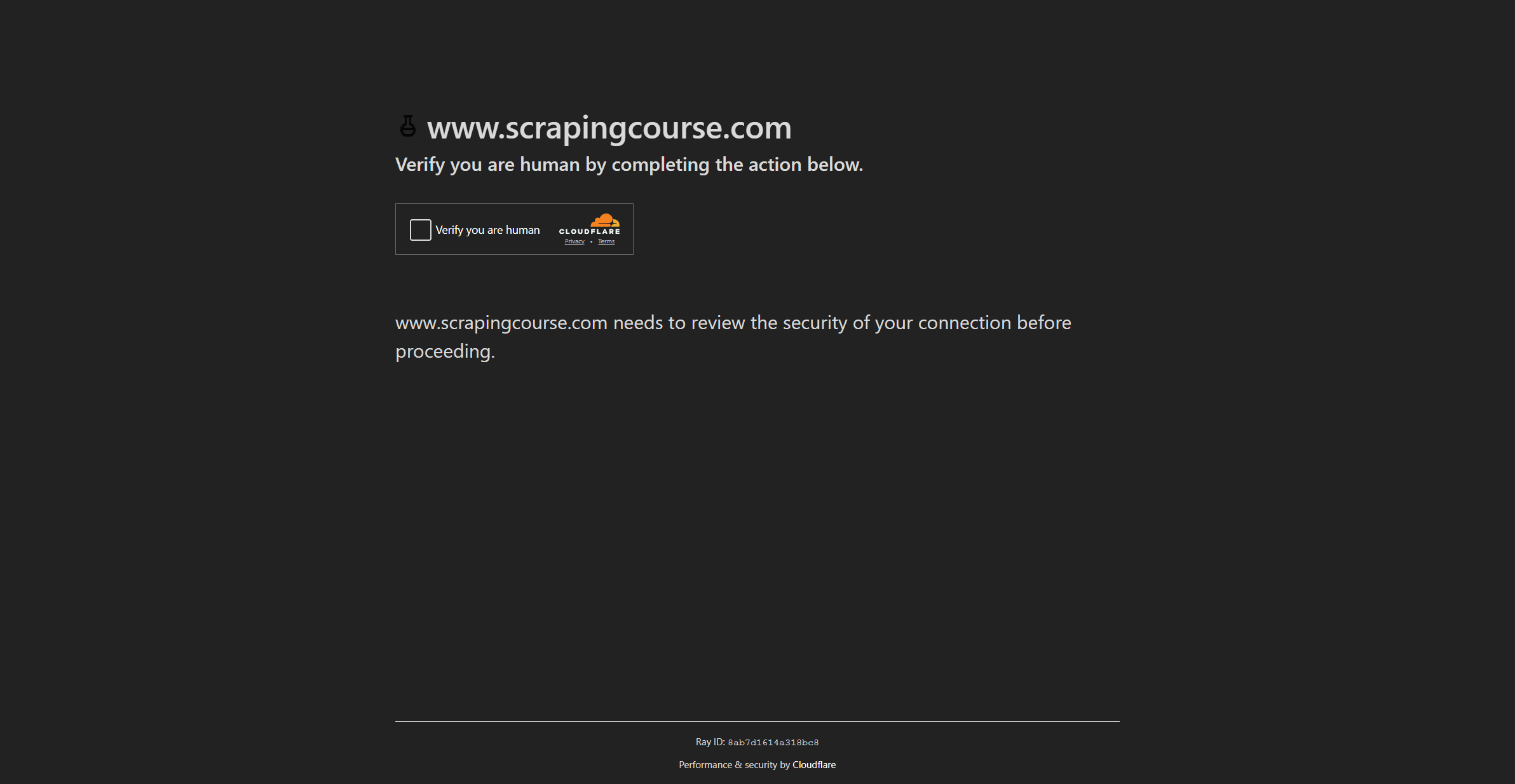
The most reliable way to bypass any anti-bot measure, regardless of its complexity, is to use a web scraping solution, such as the ZenRows Universal Scraper API. ZenRows enables you to consistently access the data you need at scale with zero maintenance effort.
With just a few steps, ZenRows applies all the necessary evasion techniques to bypass any anti-bot measures. This allows you to focus on core business logic rather than wasting time and resources on fixing broken pipelines or manually patching automation loopholes. It also has headless browser features for handling dynamic rendering and automating user interactions.
Sign up with ZenRows and go to the Playground, then paste the target URL in the link box, and activate Adaptive Stealth Mode.
Select your programming language and choose the API connection mode. Copy and paste the generated code into your scraper script:
# pip3 install requests
import requests
url = "https://www.scrapingcourse.com/antibot-challenge"
apikey = "<YOUR_ZENROWS_API_KEY>"
params = {
"url": url,
"apikey": apikey,
"mode": "auto",
}
response = requests.get("https://api.zenrows.com/v1/", params=params)
print(response.text)
# ...continue your scraping logic
The above code gives the following result, showing you bypassed the anti-bot measure:
<html lang="en">
<head>
<!-- ... -->
<title>Antibot Challenge - ScrapingCourse.com</title>
<!-- ... -->
</head>
<body>
<!-- ... -->
<h2>
You bypassed the Antibot challenge! :D
</h2>
<!-- other content omitted for brevity -->
</body>
</html>
You've now integrated ZenRows and can scrape any website without limitations.
Conclusion
Playwright is a popular headless browsing tool. However, its default properties make it easily detectable by target websites. To avoid getting blocked, you need to make it stealthier by masking those loopholes.
Yet, Playwright Stealth falls short against advanced anti-bot systems. To extract data reliably, we recommend using a functional, easy-to-use solution like ZenRows.
FAQ
Why Use Playwright Stealth?
You should use Playwright Stealth because it patches the obvious automation signals in the base Playwright version. While this may not guarantee consistent anti-bot bypass, it increases your chances of evading initial detection.
Is Playwright Stealth Undetectable?
No, despite patching Playwright's bot-like fingerprints, the stealth plugin still leaves some loopholes that advanced anti-bot measures can't overlook.
What Is the Best Way to Avoid Detection in Playwright?
The easiest and most reliable way to avoid detection during scraping is to use a ready-made solution, such as a scraper API. Unlike open-source solutions, these are consistently maintained to bypass anti-bot measures.