Are you scraping with JavaScript and considering the best library between Cheerio and Puppeteer?
In this article, you'll see the similarities and differences between both libraries to decide the best one for your web scraping project.
Cheerio vs. Puppeteer: Which Is Best?
Cheerio is a Node.js library for parsing HTML and XML documents. It uses JQuery syntax to manipulate the DOM and is handy for basic web scraping. Cheerio can't scrape JavaScript-rendered websites by default and doesn't have a built-in HTTP client. It relies on external libraries like Axios for HTTP requests.
Puppeteer is a Node.js automation library with headless browser functionalities for interacting responsively with dynamic web pages. It packs more features than Cheerio, including a built-in HTTP client for HTTP requests.
Use Cheerio for web scraping if your project is basic and doesn't require JavaScript rendering. It has an easier learning curve and is suitable for quick scraping. Scraping with Puppeteer works best when the target website uses JavaScript to load content. Choose Puppeteer if your project requires interactivities like clicking and scrolling to access the target data.
Overview: Cheerio vs. Puppeteer
Let's briefly compare both web scraping libraries in the table below:
| Consideration | Cheerio | Puppeteer |
|---|---|---|
| Learning curve | Easier | Steeper |
| HTTP client | Not built-in. It relies on external clients like Axios | Yes |
| JavaScript support | No | Yes |
| Browser | None | Yes |
| Avoid getting blocked | User-agent rotation, premium proxy integration | Puppeteer Stealth plugin, premium proxies, header rotation |
| Speed | Fast | Slower |
| Community | Good | Good |
Keep reading to see a more detailed comparison between Cheerio and Puppeteer.
Similarities Between Cheerio and Puppeteer
Cheerio and Puppeteer share some similarities that make them powerful web scraping tools. Let's discuss them in more detail.
Both are Node.js Libraries
Puppeteer and Cheerio are Node.js libraries for web scraping in JavaScript. Thus, you can integrate them flawlessly into Node.js applications for web scraping functionalities. Additionally, anyone with a JavaScript background can pick them up quickly.
They Offer Powerful HTML Parsing Capabilities
Both tools parse HTML documents effectively. However, Cheerio relies on external HTTP clients like Axios for HTTP requests. It uses JQuery-like syntax to manipulate and extract data from static web pages.
Puppeteer has a built-in HTTP client and makes requests independently. It relies on its page instance methods or JavaScript injections to interact with dynamic web pages and extract content from them.
Let's quickly compare their HTML parsing capabilities by extracting product names and prices from ScrapeMe.
In the code below, Cheerio parses HTML from Axios (HTTP client) before scraping its content:
// import the required libraries
const axios = require('axios');
const cheerio = require('cheerio');
// specify the URL to scrape
const url = 'https://scrapeme.live/shop/';
axios.get(url)
.then(response => {
// load the HTML content into Cheerio
const $ = cheerio.load(response.data);
// select all product cards
const productContainers = $('.woocommerce-LoopProduct-link');
// iterate over each product container
productContainers.each((index, element) => {
// find the name element within the current product container
const nameElement = $(element).find('.woocommerce-loop-product__title');
const name = nameElement.text().trim();
// find the price element within the current product container
const priceElement = $(element).find('.price');
const price = priceElement.text().trim();
// print the name and price of the product
console.log('Name:', name);
console.log('Price:', price);
});
})
.catch(error => {
console.error('Error fetching HTML:', error);
});
The code below extracts similar content using Puppeteer. Here, Puppeteer spins a browser instance and handles HTTP request and parsing independently:
// import the required library
const puppeteer = require('puppeteer');
// specify the target URL
const url = 'https://scrapeme.live/shop/';
(async () => {
// launch the browser
const browser = await puppeteer.launch();
try {
// open a new page
const page = await browser.newPage();
// navigate to the webpage
await page.goto(url);
// wait for the page to load completely
await page.waitForSelector('.woocommerce-LoopProduct-link');
// extract all product containers
const productContainers = await page.$$('.woocommerce-LoopProduct-link');
for (const productContainer of productContainers) {
// find the name element within the current product container
const nameElement = await productContainer.$('.woocommerce-loop-product__title');
const name = nameElement ? await page.evaluate(element => element.textContent.trim(), nameElement) : '';
// find the price element within the current product container
const priceElement = await productContainer.$('.price');
const price = priceElement ? await page.evaluate(element => element.textContent.trim(), priceElement) : '';
// print the name and price of the product
console.log('Name:', name);
console.log('Price:', price);
}
} catch (error) {
console.error('Error:', error);
} finally {
// close the browser
await browser.close();
}
})();
Let's see some more similarities between the duo.
Support for Asynchronous Operations
Puppeteer uses JavaScript's event-driven model and promises to execute scraping tasks asynchronously. Although Cheerio isn't asynchronous by default, you can pair it with an HTTP client like Axios to confer asynchronous behavior.
Thus, both tools can operate without blocking the application thread, improving overall content extraction performance.
Both Have Active Developer Communities
Both libraries have active community support, with only a slight difference in popularity. It ensures a continuous contribution and improvement to their web scraping capabilities.
Statistics from npmtrends show that Cheerio has higher usage stats with 7.8 million weekly downloads, while Puppeteer tails with 4.7 million weekly downloads.
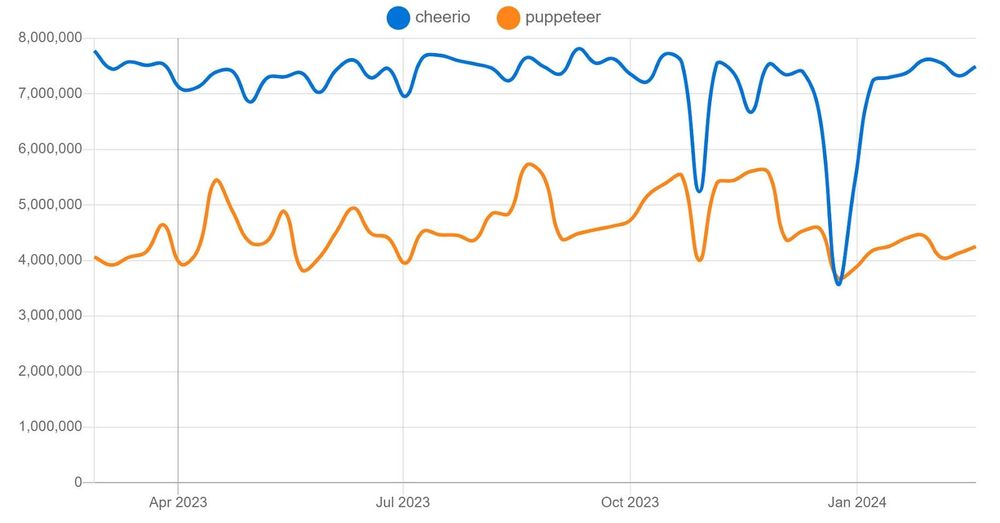
Source: npmtrends
Now, you've seen the similarities between Cheerio and Puppeteer. You also need to know how they differ.
Main Differences: Cheerio and Puppeteer
Despite the similarities between both tools, some differences are worth considering before choosing either.
Puppeteer Can Render JavaScript-Based Content and Pages
Many modern websites use JavaScript to load content dynamically from the database. Puppeteer scrapes such dynamic websites seamlessly. It has browsing functionalities, allowing it to interact with page elements and execute actions like scrolling and clicking.
Cheerio is only a parsing library and doesn't have the browser capabilities to interact dynamically with web pages. While it can manipulate web elements, it can't execute JavaScript code or actions like clicking or scrolling.
Cheerio Is Easier to Learn
Cheerio has straightforward APIs for manipulating the DOM. It uses JQuery-like syntaxes, which is easier to learn for beginners and anyone with a JQuery background.
Although Puppeteer has more features and scraping strength than Cheerio, it's more complex because you'll have to handle extra browser instance setup, navigations, and page lifecycle events. This makes it less beginner-friendly and complicates its learning curve.
Cheerio Is Blazing Fast Compared to Puppeteer
Cheerio is faster in parsing HTML content because it doesn't handle extra browser instance overhead and has simple features. While Puppeteer handles dynamic content scraping better, its comprehensive features and requirements for a browser instance make it slower than Cheerio.
We performed a 100-iteration benchmark to compare the HTML parsing speed of Puppeteer vs. Cheerio. Cheerio was significantly faster at an average time of 336.8ms. It took Puppeteer an average of 1699.5ms to parse the same content.
See the graphical representation of the benchmark below (from the fastest to the slowest):

The time unit used is the millisecond (1000 ms = 1s)
Keep in mind that anti-bots will limit your web scraper. Next, you'll see how each tool bypasses blocks.
Best Choice to Avoid Getting Blocked While Scraping
Websites use various anti-bot mechanisms to detect and block web scrapers. You must bypass them to scrape the data you want.
Cheerio and Puppeteer offer different ways of avoiding anti-bot detection. Cheerio leverages HTTP clients like Axios to rotate the user agent and configure premium proxies to avoid getting blocked.
You can avoid detection in Puppeteer by fixing custom headers, rotating the user agent, and using premium proxies. It also has the Puppeteer Stealth plugin that features various evasions for bypassing anti-bot technologies.
However, you can still get blocked even after implementing all these methods. A solution that works all the time is to integrate a web scraping API like ZenRows. It provides headless browser capabilities, fixes the request headers, configures premium proxies, and bypasses CAPTCHAs and other anti-bot measures with a simple API call.
Conclusion
In this article, you've seen the differences and similarities between Puppeteer and Cheerio. Both are Node.js libraries with powerful parsing capabilities, active community, and support for asynchronous tasks. While Puppeteer is better at scraping dynamic websites, Cheerio is faster and more beginner-friendly.
Remember that anti-bots will block your scraper regardless of your chosen library. ZenRows is the all-in-one web scraping solution for bypassing any detection system. It supports several programming languages and integrates well with Cheerio and Puppeteer. Try ZenRows for free
Did you find the content helpful? Spread the word and share it on Twitter, or LinkedIn.