How to Make Firefox Headless with Python Selenium
Learn how to use Firefox as a headless browser to add interactivity to your web scraper programmatically and avoid being blocked.
Firefox remains one of the most popular web browsers in 2024 and comes with a useful tool to help web scrapers: headless mode.
In this tutorial, we'll cover when to use and how to run headless Firefox with Selenium in Python. Let's dive in!
What Is Headless Firefox?
Headless Firefox essentially means that we won't use the browser in a conventional way. Instead, we'll employ a WebDriver tool to operate it without the user interface. That's the difference between running Firefox headless and standard.
What Is a Browser in Headless Mode? Let's Talk Benefits
A web browser client without a graphical user interface (GUI) is a headless browser used to aid scripts or bots.
Operating the web browser is necessary for most scrapers since you usually need to scroll, fill forms and perform similar actions. Also, it helps you save machine resources, especially when executing large tasks.
Can Firefox Run Headless? And How?
Yes, it can. Some web browser automation tools support the Firefox browser, like Selenium. It provides us with Firefox's headless WebDriver to secure the connection to the browser.
Chrome is the most used browser for running headless because it has a larger ecosystem with more automation tools, such as undetected_chromedriver and puppeteer-extra-plugin-stealth.
However, Firefox is used as an alternative to Chrome for running browsers in headless mode. That's because it has many tools for the same purpose using Python or other languages.
The most popular tools to run Firefox headless are Selenium and Playwright. We'll also mention Puppeteer because it's wildly adopted in other languages, yet it only offers experimental support for this browser.
How Do I Start Firefox Headless?
The prerequisites to start running Firefox headless are to install Python and Selenium (the library we'll use in this tutorial). You also need to make sure the Firefox browser is installed on your local machine.
Selenium WebDriver serves as a web automation tool, allowing you to manage web browsers. Selenium WebDriver, previously requiring manual installation, is now automatically included in versions 4 and above. To access the latest functionalities, update to the newest version by using the command pip show selenium to check your current version and pip install --upgrade selenium to upgrade.
pip install selenium
With that done, using the code editor of your choice, we'll use ScrapingCourse.com, a demo website with e-commerce features. Write the script you'll see next, but let's understand what happens first:
Selenium's default Firefox WebDriver loads the browser, and the Options interface allows us to run it in the background by passing in headless as an argument. Once the target website has been loaded, the WebDriver will redirect the browser to print the current URL and title.
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
# the target website
url = "https://www.scrapingcourse.com/ecommerce/"
# the interface for turning on headless mode
options = Options()
options.add_argument("-headless")
# using Firefox headless webdriver to secure connection to Firefox
with webdriver.Firefox(options=options) as driver:
# opening the target website in the browser
driver.get(url)
#printing the target website url and title
print(driver.current_url) # https://www.scrapingcourse.com/ecommerce/
print(driver.title) # Products - ScrapingCourse
To run Firefox in normal mode, you comment out or remove the headless option as shown below:
# ...
url = "https://www.scrapingcourse.com/ecommerce/"
# options = Options()
# options.add_argument("-headless")
with webdriver.Firefox() as driver:
# ...
In our case, we run Firefox headless!
Skip the blocks. Try Zenrows free and get clean web data without the anti-bot fight.
What Does Running Firefox Headless Give Me?
Running the browser headless should give you the same result as running it in normal mode with a GUI.
The exception would be if you're running cross-browser tests on your website, and there are initial expectations that your website could behave differently across different browser environments. But most websites are optimized to behave the same way across all major browsers to ensure a good user experience.
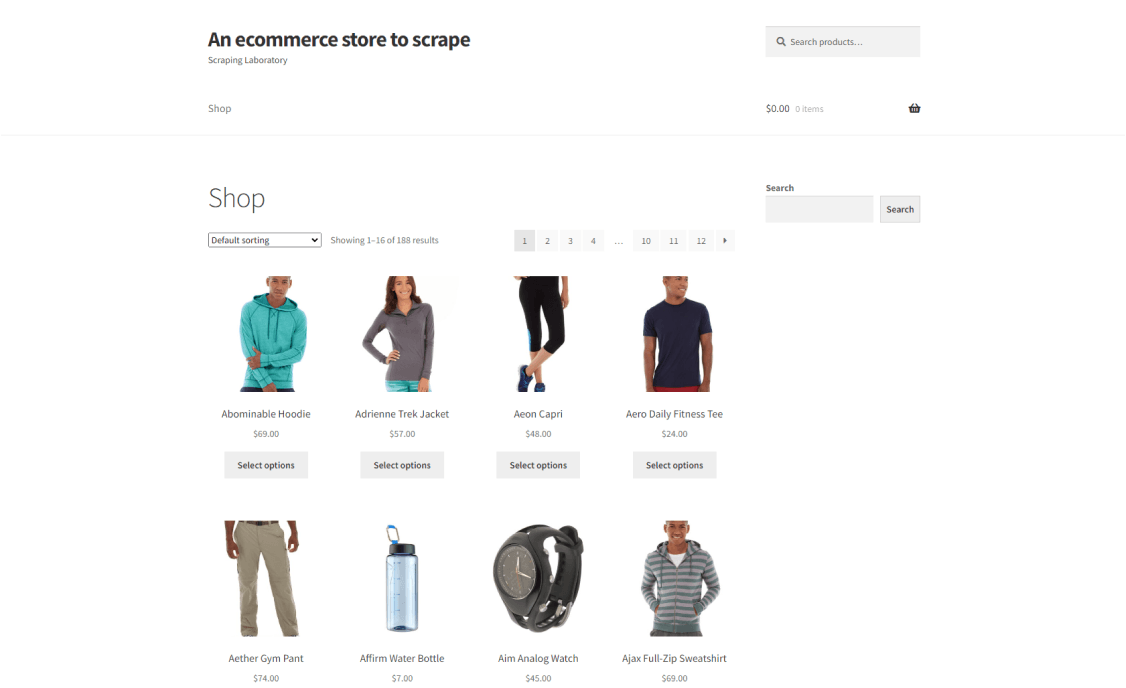
Let's imagine we're interested in the product information from ScrapingCourse.com, specifically in the product names and prices on the page.
On Inspection, we discovered three-page elements to enable us to extract these sets of data:
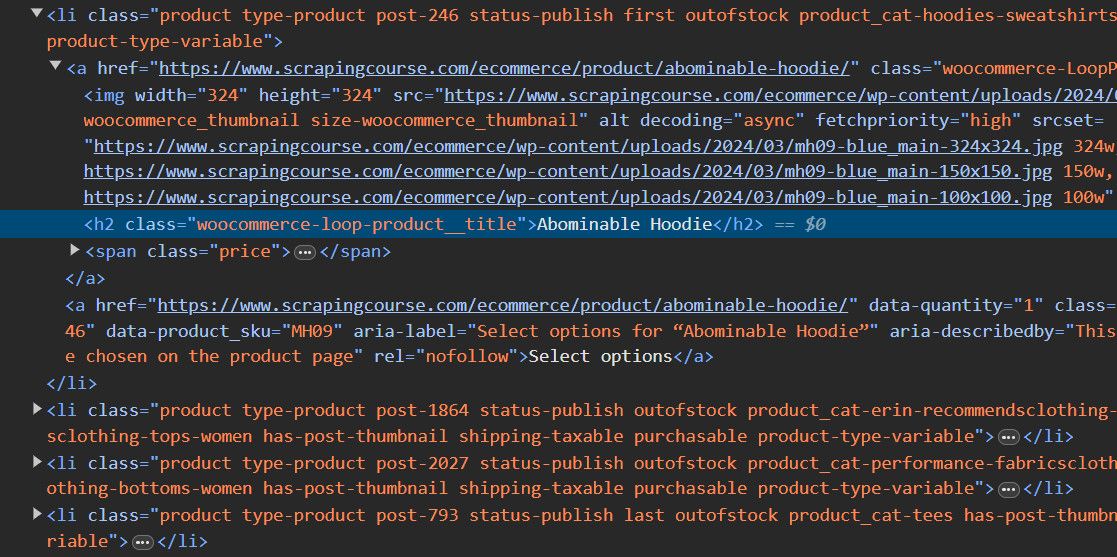
First, the parent element that contains the product names and prices:
<a href="https://www.scrapingcourse.com/ecommerce/" class="woocommerce-LoopProduct-link woocommerce-loop-product__link"> ... </a>
The product names are h2 elements:
<h2 class="woocommerce-loop-product__title"> ... </h2>
The product prices are span elements:
<span class="woocommerce-Price-amount amount"><span class="woocommerce-Price-currencySymbol">£</span> ... </span>
To extract the information from the page, we'll use XPath in Selenium to select the elements:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.options import Options
# the target website
url = "https://www.scrapingcourse.com/ecommerce/"
# the interface for turning on headless mode
options = Options()
options.add_argument("-headless")
# using Firefox headless webdriver to secure connection to Firefox
with webdriver.Firefox(options=options) as driver:
# opening the target website in the browser
driver.get(url)
print("Page URL:", driver.current_url)
print("Page Title:", driver.title)
# using Selenium's find_elements() API to find the parent element
product_list = driver.find_elements(By.XPATH, "//a[@class='woocommerce-LoopProduct-link woocommerce-loop-product__link']")
# using Seleniumm's find_element() API to locate each of the child elements
for product in product_list:
product_name = product.find_element(By.XPATH, ".//h2")
product_price = product.find_element(By.XPATH, ".//span")
# parsing the extracted data into a python dictionary
clones = {
"name": product_name.text,
"price": product_price.text
}
print(clones)
Here's our scraped data:
Page URL: https://www.scrapingcourse.com/ecommerce/
Page Title: Ecommerce Test Site to Learn Web Scraping – ScrapingCourse.com
{'name': 'Abominable Hoodie', 'price': '$69.00'}
{'name': 'Adrienne Trek Jacket', 'price': '$57.00'}
#... other products omitted for brevity
{'name': 'Artemis Running Short', 'price': '$45.00'}
{'name': 'Pidgey', 'price': '£159.00'}
For many internet sites, you'll have to deal with anti-bot protections like WAFs (Web Application Firewalls). To learn some actionable tricks, check our guide section on how to avoid being detected using headless browsers.
Conclusion
Making Firefox headless with Python Selenium is one of the best options to automate web browser tasks in web scraping. And we learned how to extract data using them.
Many developers also try a web scraping API to bypass all sorts of protections and save resources. For example, ZenRows{:data-popup=true} provides access to premium proxies, CAPTCHA bypass, and other challenges you'll face along the way.